2023
06-24
06-24
看过三体吗?代谢组学解决方案也能那么科幻
 时维深冬,蒹葭仍苍,想到诗经中的意境,小编禁不住要为我们的产品赋一首属于这个季节的古风歌。彼组学之华兮,在水一方。求之不得兮,寤寐思服。爰赛默飞解决方案之厥功兮,大功可期。——吴泽明赛默飞代谢组学解决方案之蒙太奇——三体舰队来袭!列位客官也看出来了小编是个玩质谱的文青。今天小编我就用电影镜头语言来重现赛默飞代谢组学解决方案的三个应用场景。小编爱质谱也爱科幻,近期在二刷偶像大刘的《三体》。想着 ..... 阅 读 全 部 >
时维深冬,蒹葭仍苍,想到诗经中的意境,小编禁不住要为我们的产品赋一首属于这个季节的古风歌。彼组学之华兮,在水一方。求之不得兮,寤寐思服。爰赛默飞解决方案之厥功兮,大功可期。——吴泽明赛默飞代谢组学解决方案之蒙太奇——三体舰队来袭!列位客官也看出来了小编是个玩质谱的文青。今天小编我就用电影镜头语言来重现赛默飞代谢组学解决方案的三个应用场景。小编爱质谱也爱科幻,近期在二刷偶像大刘的《三体》。想着 ..... 阅 读 全 部 >
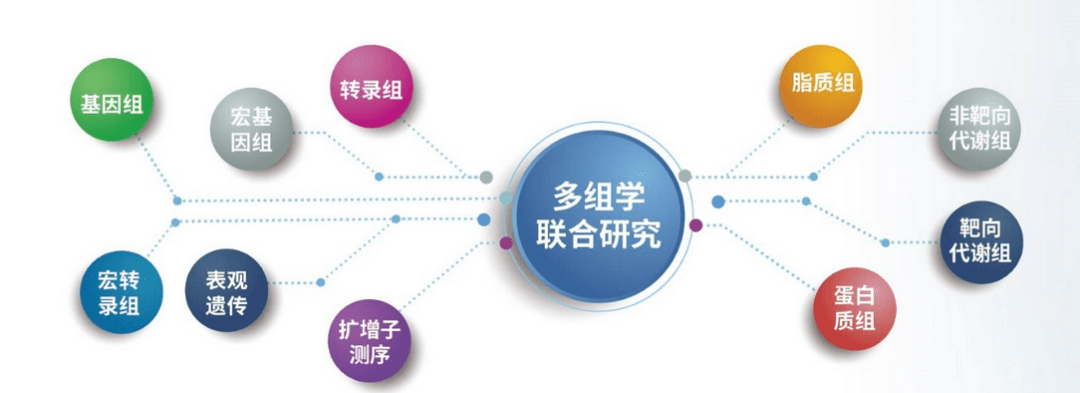 代谢组是对生物体内代谢产物全谱分析的一种研究手段,代谢产物包括核酸、蛋白质、脂类生物大分子以及其他小分子物质,目前主要是检测1000Da以下的物质。代谢组研究具有高通量的检测能力、高灵敏度和准确度、非侵入性、非破坏性、全面性、数据资源整合等特点。通过LC-MS/GC-MS评估生物体或细胞产生的代谢产物的水平以及变化,可以进一步研究这些代谢产物与转录组学差异基因或微生物的关系。在这个系统生物学......
代谢组是对生物体内代谢产物全谱分析的一种研究手段,代谢产物包括核酸、蛋白质、脂类生物大分子以及其他小分子物质,目前主要是检测1000Da以下的物质。代谢组研究具有高通量的检测能力、高灵敏度和准确度、非侵入性、非破坏性、全面性、数据资源整合等特点。通过LC-MS/GC-MS评估生物体或细胞产生的代谢产物的水平以及变化,可以进一步研究这些代谢产物与转录组学差异基因或微生物的关系。在这个系统生物学......  我们知道在代谢组学实验鉴定后,原始数据经软件解析后将得到代谢离子以及二级碎片离子的谱图信息,如:离子的质荷比(m/z)、保留时间(Retention time)及在信号强度值(intensity)等,通过与数据库中一二级代谢物的谱图信息进行匹配,来确定检测到哪些代谢物。但在谱图匹配中一定少不了数据库,继上期小编分享了四连发 | 新鲜出炉!同一期刊连发4篇,鹿明LC-MS非靶向代谢“...阅读全文&...
我们知道在代谢组学实验鉴定后,原始数据经软件解析后将得到代谢离子以及二级碎片离子的谱图信息,如:离子的质荷比(m/z)、保留时间(Retention time)及在信号强度值(intensity)等,通过与数据库中一二级代谢物的谱图信息进行匹配,来确定检测到哪些代谢物。但在谱图匹配中一定少不了数据库,继上期小编分享了四连发 | 新鲜出炉!同一期刊连发4篇,鹿明LC-MS非靶向代谢“...阅读全文&... 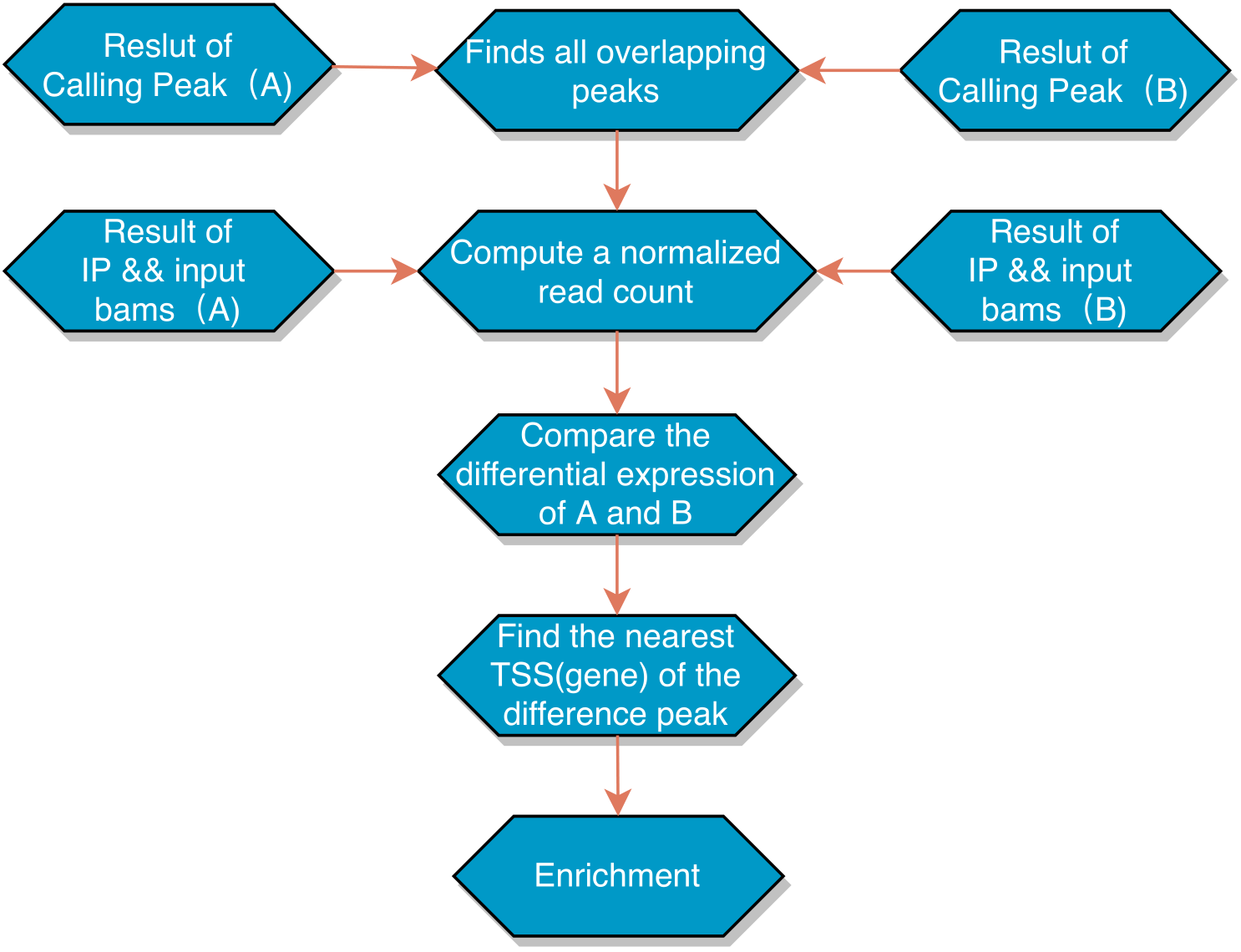 1. 概述1.1. 背景及分析流程简介为了理解细胞中更为复杂的生物过程,许多研究已在通过比较ChIP-seq的差异获得的不同数据。越来越多的ChIP-seq实验正在研究多种实验条件(例如各种治疗条件,几个不同的时间点和不同的治疗剂量水平)下的转录因子结合,组蛋白修饰的差异。差异富集在生物学和医学研究中已变得具有实际重要性。为了建立对比条件消除误差,我们对数据进行了以下流程处...阅读全文>&...
1. 概述1.1. 背景及分析流程简介为了理解细胞中更为复杂的生物过程,许多研究已在通过比较ChIP-seq的差异获得的不同数据。越来越多的ChIP-seq实验正在研究多种实验条件(例如各种治疗条件,几个不同的时间点和不同的治疗剂量水平)下的转录因子结合,组蛋白修饰的差异。差异富集在生物学和医学研究中已变得具有实际重要性。为了建立对比条件消除误差,我们对数据进行了以下流程处...阅读全文>&... 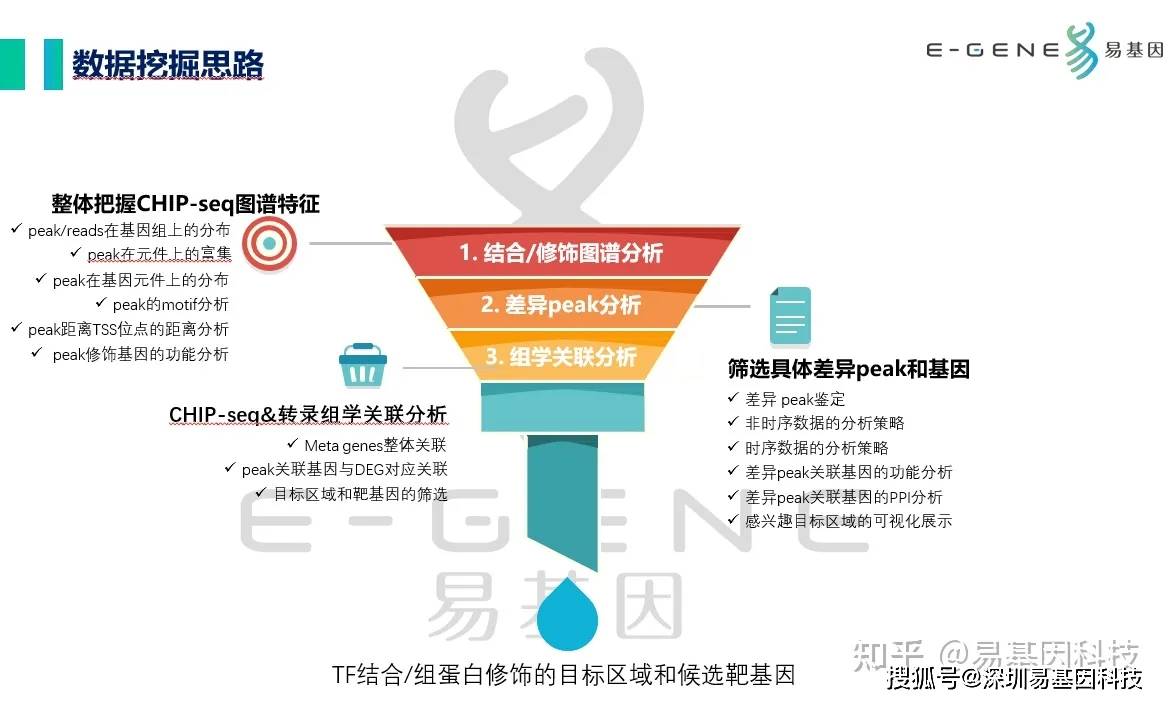 大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。CHIP-seq研究的数据挖掘思路主要分为3步:整体把握CHIP-seq图谱特征:peak/reads在基因组上的分布、peak在元件上的富集、peak在基因元件上的分布、peak的motif分析、peak距离TSS位点的距离分析、peak修饰基因的功能分析筛选具体差异peak和基因:差异peak鉴定、非时序数据的...阅读全文>...
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。CHIP-seq研究的数据挖掘思路主要分为3步:整体把握CHIP-seq图谱特征:peak/reads在基因组上的分布、peak在元件上的富集、peak在基因元件上的分布、peak的motif分析、peak距离TSS位点的距离分析、peak修饰基因的功能分析筛选具体差异peak和基因:差异peak鉴定、非时序数据的...阅读全文>...  01前言实际的科研项目中不可能只有一个样本,多样本的单细胞数据如何合并在一起,是否需要校正批次效应呢?先上一张图说明多样本scRNA数据的批次效应:左边的图简单地把多个单细胞的数据合并在一起,不考虑去除批次效应,样本之间有明显的分离现象。右边的图是使用算法校正批次效应,不同的样本基本融和在一起了。scRNA数据校正批次效应的算法有很多:MNN, CCA+MNN, Harmony, Scanor.....
01前言实际的科研项目中不可能只有一个样本,多样本的单细胞数据如何合并在一起,是否需要校正批次效应呢?先上一张图说明多样本scRNA数据的批次效应:左边的图简单地把多个单细胞的数据合并在一起,不考虑去除批次效应,样本之间有明显的分离现象。右边的图是使用算法校正批次效应,不同的样本基本融和在一起了。scRNA数据校正批次效应的算法有很多:MNN, CCA+MNN, Harmony, Scanor..... 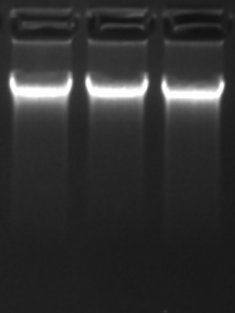 本文主要介绍了16S的实验、建库、数据分析等过程,也是我自己近期的一个小总结,初学之时从很多前辈的无私分享中受益良多,在此也和大家分享一些我的见解,当然我也只是一个初学者,还有很多不完备之处,希望能与各位一起交流分享。导航本文一共分为三个部分:实验部分建库测序16S测序数据分析一. 实验部分:DNA提取与质检1...阅读全文>>...
本文主要介绍了16S的实验、建库、数据分析等过程,也是我自己近期的一个小总结,初学之时从很多前辈的无私分享中受益良多,在此也和大家分享一些我的见解,当然我也只是一个初学者,还有很多不完备之处,希望能与各位一起交流分享。导航本文一共分为三个部分:实验部分建库测序16S测序数据分析一. 实验部分:DNA提取与质检1...阅读全文>>...  我们接着讲生物信息学的资源,之前我们介绍了NCBI,欧洲也有一个非常大的centralized resource,叫EBI 。和NCBI有点类似,也是一个包含各种各样数据库这样的资源,它主要也是针对从序列到蛋白到蛋白结构到表达到通路到Ontology各个方面。首先在DNA,RNA和蛋白的方面,基因和基因组最主要是有一个ensembl,很多人不知道EBI也会知道ensemb...阅读全文>&g...
我们接着讲生物信息学的资源,之前我们介绍了NCBI,欧洲也有一个非常大的centralized resource,叫EBI 。和NCBI有点类似,也是一个包含各种各样数据库这样的资源,它主要也是针对从序列到蛋白到蛋白结构到表达到通路到Ontology各个方面。首先在DNA,RNA和蛋白的方面,基因和基因组最主要是有一个ensembl,很多人不知道EBI也会知道ensemb...阅读全文>&g...  2022年10月4日, Nature Genetics在线发表了德国莱布尼茨植物遗传与作物研究所(IPK)Jochen C. Reif和Martin Mascher联合团队及其合作者题为“ Genomics-informed prebreeding unlocks the diversity in genebanks for wheat improvement ”的研究论文。该研究通过对大量......
2022年10月4日, Nature Genetics在线发表了德国莱布尼茨植物遗传与作物研究所(IPK)Jochen C. Reif和Martin Mascher联合团队及其合作者题为“ Genomics-informed prebreeding unlocks the diversity in genebanks for wheat improvement ”的研究论文。该研究通过对大量...... 