上次小编给大家介绍了,大家看过之后是不是也有一种想发高分文章的冲动?古语云“九层之台,起于累土”,今天小编就给大家重点介绍一下好文章背后的故事------PacBio三代测序的文库制备。
首先,我们来认识一下三代测序的文库结构,与二代测序线状的文库结构不同,三代测序的文库是“哑铃型”的环状结构,中间是插入片段,两端分别是茎环结构的接头(图 1)。这种“哑铃型”文库是三代文库设计的最大亮点,环状的文库设计完美地契合了PacBio三代超长读长(平均读长10-12kb)的测序优势,当文库插入片段小于聚合酶读长时(短片段插入),酶的活性足以支撑它读完整个片段后还可以继续沿着环形文库循环读下去,从而实现对插入片段的反复测序进而获得高准确度的单分子测序结果。那么,这种“哑铃型”的文库是如何制备得到的呢,现在小编就给大家详细介绍。
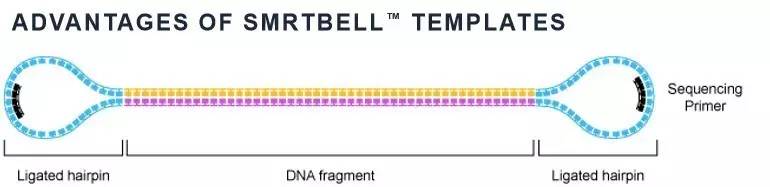
图1 三代测序“哑铃型”的文库结构
基因组测序文库构建
将基因组DNA打断破碎成大片段(通常是20kb左右),之后经过末端修复、接头连接、片段筛选、杂交测序引物和DNA聚合酶绑定(图 2),我们的SMRT Bell DNA文库就制备成功了。小编想问大家有没有注意到,整个文库构建过程没有经过PCR,对喽,这是三代基因组测序文库构建的最大亮点!
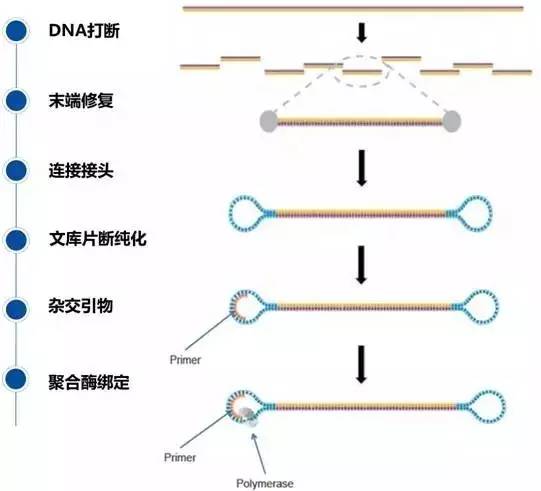
图2 基因组文库构建流程
全长转录组测序文库构建
与基因组DNA文库制备相比,全长转录组的文库制备要复杂那么一丢丢~首先,我们需要从总RNA中筛选获得polyA(+)RNA,之后利用SMARTer™PCR cDNA Synthesis Kit进行反转录合成cDNA。cDNA合成后需要使用KAPA HiFi PCR Kit进行PCR扩增,扩增后按片段大小对cDNA进行分选,为保证获得足够量的cDNA进行后续建库测序,分选后cDNA片段经过PCR再次扩增,之后经过末端修复、接头连接、片段筛选、杂交测序引物和DNA聚合酶绑定就可以上机测序了(图3)。
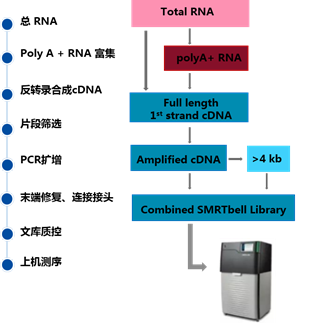
图3 全长转录组测序文库构建流程
小编在这里告诉大家:与二代RNA-seq文库构建不同,全长转录组的建库过程不需要对片段进行打断破碎,测序得到的是完整的RNA分子全长。哇,是不是有点不可思议,长读长测序就是这么赞!另外,全长转录组建库过程增加了片段分选的步骤,通常会构建获得1-2个文库,这是因为测序的时候小片段文库更容易落入零模波导孔(ZMW),为了避免测序对小片段的偏好性,保证不同长度的转录本都能均匀的覆盖到,在经费充足的情况下,通常建议构建两个不同片段大小的文库。
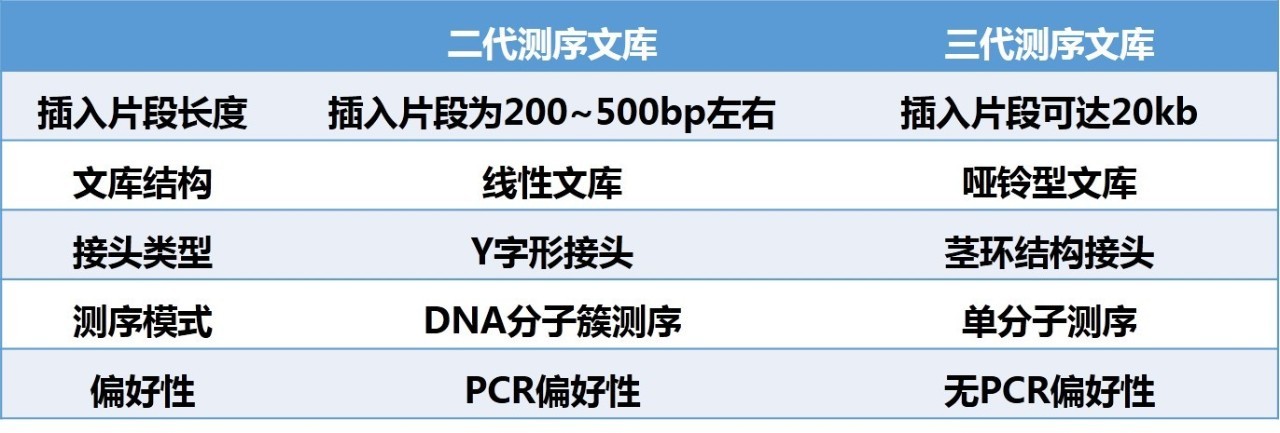
小编在这里啰嗦了这么久,重点大家都Get 到了吗?再看看下面的表格,是不是就胸有成竹了~
表1 二代测序文库和三代测序文库对比
安诺基因在三代测序项目中积累了丰富的项目经验,拥有成熟的建库和数据分析流程,2017年安诺基因将会引入PacBio Sequel测序平台,我们会利用领先的二代及三代测序平台,为大家提供高质量的测序服务,满足广大科研工作者们的研究需求,一切只为助力科研。
文案:三代测序产品经理 辛颖
- 本文固定链接: https://maimengkong.com/zu/1991.html
- 转载请注明: : 萌小白 2025年7月27日 于 卖萌控的博客 发表
- 百度已收录
