作者:鲁伟,热爱数据,坚信数据技术和代码改变世界。R语言和Python的忠实拥趸,为成为一名未来的数据科学家而奋斗终生。个人公众号:数据科学家养成记 (微信ID:louwill12)
第三篇戳:R语言爬虫系列3|HTTP协议
无论是R中的RCurl组件还是Python的BeautifulSoup库,对网页HTML完成下载解析之后我们从这些看似杂乱无章的文本中拿到我们感兴趣的数据。之前在系列2的时候小编就已经跟大家介绍过HTML/XML专用工具XPath表达式,今天小编需要跟大家介绍一款更为通用、更加底层的文本信息提取工具——正则表达式。
所谓正则表达式,即使用一个字符串来描述、匹配一系列某个语法规则的字符串。通过特定的字母、数字以及特殊符号的灵活组合即可完成对任意字符串的匹配,从而达到提取相应文本信息的目的。在R语言中,有两种风格的正则表达式可以实现,一种就是在基本的正则表达式基础上进行扩展,这和相应的R字符串处理函数相关,另一种就是Perl正则表达式,这种风格的正则我们在R中一般不常用,本文主要还是针对R默认的基础的正则表达式风格进行讲解。
R默认的正则表达式风格包括基础文本处理函数和stringr包中的文本处理函数。在R中二者都支持正则表达式,也都具备基本的文本处理能力,但基础函数的一致性要弱很多,在函数命名和参数定义上很难让人印象深刻。stringr包是Hadley Wickham开发了一款专门进行文本处理的R包,它对基础的文本处理函数进行了扩展和整合,在一致性和易于理解性上都要优于基础函数。本文在介绍基本的正则表达式语法的基础上,通过R中这两种文本处理函数进行实例说明,也好让大家对R语言中正则表达式的基本用法有个大致了解,在后续的爬虫演练中更容易理解一些信息提取的细节知识。
基本的正则表达式语法
实际应用中正则表达式的一个比较经典的使用场景是识别电子邮箱地址。一个正常的电子邮箱账户应该由下面几部分构成:任意字符、数字和符号组成的用户名+@+.+com/net等域名。根据正则表达式的语法规则,我们就可以由这几部分写出邮箱账户的正则表达式:
[A-Za-z0-9._+]+@[A-Za-z0-9]+.(com|org|edu|net)
其中:
[A-Za-z0-9._+]+:A-Z表示匹配任意的A-Z大写字母,所有可能的组合放在中括号里表示可以匹配其中的任一个,加号表示任意字符可以出现1次或者多次,表示转义,因为.在正则表达式中有特殊含义,想要正常的表达.号必须使用转义符。
@:邮箱必须的一个符号。
[A-Za-z0-9]:同前面一样,@符号后面必须有一个包含运营商信息的字符串。
.:邮箱地址中必须要有的一个点号。
(com|org|edu|net):列出邮箱地址可能的域名系统,括号内表示分组处理,|符号表示或的含义。
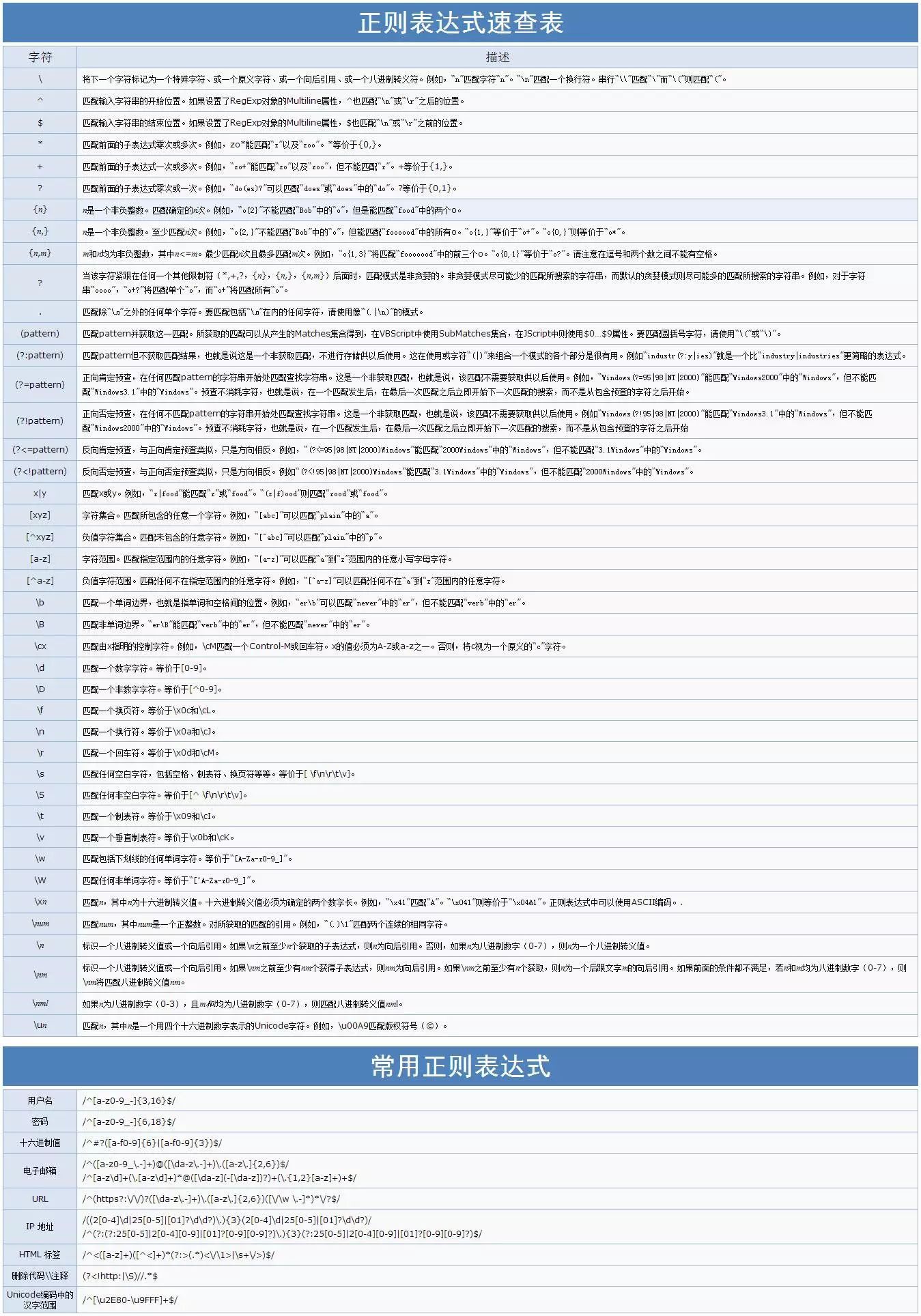
小编这里需要简单的列一下基本的正则表达式语法,这几个语法作为正则表达式的基础,必须用心记下来,并用一些简单的例子加深印象,是需要熟练掌握的。正则表达式速查表,参考信息来自:
http://www.jb51.net/shouce/jquery1.82/regexp.html
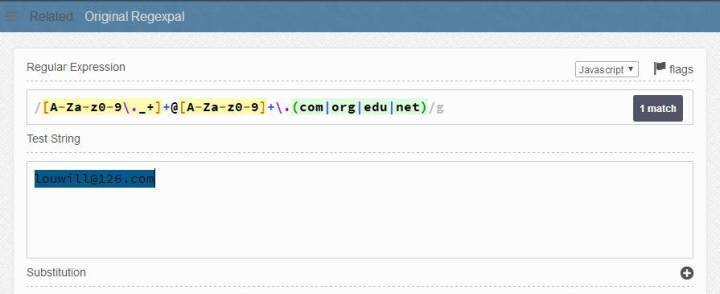
另外也有一些在线测试正则表达式的网页,大家可以拿来练手,小编这里也推荐一个:
https://www.regexpal.com/
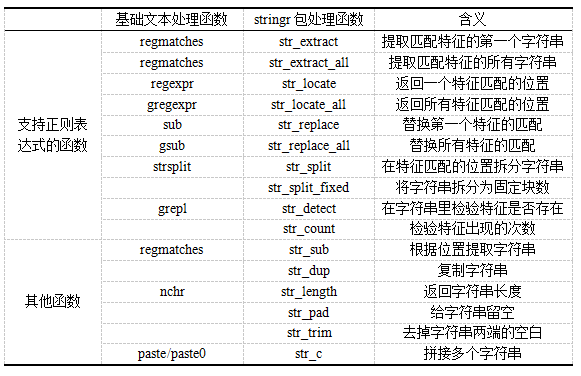
R中基础文本处理函数和stringr包文本处理函数对于正则表达式的支持情况如下表所示:
基础文本处理函数中正则表达式的应用
R中常用的支持正则表达式的基础文本处理函数包括grep/grepl、sub/gsub、regexpr/gregexpr等。
example_text1 <- c("23333#RRR#PP","35555#CCCC","louwill#2017")
#以#进行字符串切分
unlist(strsplit(example_text1, "#"))
[1] "23333" "RRR" "PP" "35555" "CCCC" "louwill" "2017"
#以空字符集进行字符串切分
unlist(strsplit(example_text1, "s"))
[1] "23333#RRR#PP" "35555#CCCC" "louwill#2017"
#以空字符替换字符串第一个#匹配
sub("#","", example_text1)
[1] "23333RRR#PP" "35555CCCC" "louwill2017"
#以空字符集替换字符串全部#匹配
gsub("#","",example_text1)
[1] "23333RRRPP" "35555CCCC" "louwill2017"
#查询字符串中是否存在3333或5555的特征并返回所在位置
grep("[35]{4}", example_text1)
[1] 1 2
#查询字符串中是否存在3333或5555的特征并返回逻辑值
grepl("[35]{4}", example_text1)
[1] TRUE TRUE FALSE
#返回匹配特征的字符串
pattern <- "[[:alpha:]]*(,|#)[[:alpha:]]"
m <- regexpr(pattern, example_text1)
regmatches(example_text1, m)
[1] "#R" "#C"
stringr包文本处理函数中的正则表达式的应用
stringr包一共为我们提供了30个字符串处理函数,其中大部分均可支持正则表达式的应用,包内所有函数均以str_开头,后面单词用来说明该函数的含义,相较于基础文本处理函数,stringr包函数更容易直观地理解。本文仅以str_extract和str_extract_all函数为例,对stringr包的正则表达式应用进行简要说明。
example_text2 <- "1. A small sentence. - 2. Another tiny sentence."
library(stringr)
#提取small特征字符
str_extract(example_text2, "small")
[1] "small"
#提取包含sentence特征的全部字符串
unlist(str_extract_all(example_text2, "sentence"))
[1] "sentence" "sentence"
#提取以1开始的字符串
str_extract(example_text2, "^1")
[1] "1"
#提取以句号结尾的字符
unlist(str_extract_all(example_text2, ".$"))
[1] "."
#提取包含tiny或者sentence特征的字符串
unlist(str_extract_all(example_text2, "tiny|sentence"))
[1] "sentence" "tiny" "sentence"
#点号进行模糊匹配
str_extract(example_text2, "sm.ll")
[1] "small"
#中括号内表示可选字符串
str_extract(example_text2, "sm[abc]ll")
[1] "small"
str_extract(example_text2, "sm[a-p]ll")
[1] "small"
对于特定的字符我们可以手动指定,比如[a-z A-Z]表示a-z和A-Z之间的所有字母,但R预先定义了一些字符集方便大家调用,如下表所示。

str_extract(example_text2, "([[:alpha:]]).+?1")
[1] "A small sentence. - 2. A"
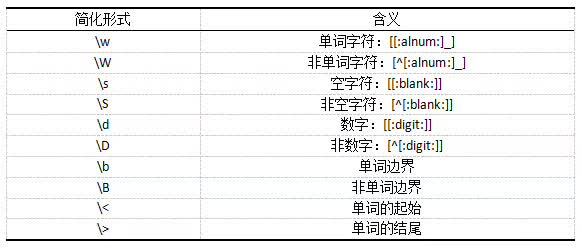
除此之外,R中正则表达式的应用还有若干简化的形式,它被分配给几个特定的字符类,如下表所示:
#提取全部单词字符
unlist(str_extract_all(example_text2, "w+"))
[1] "1" "A" "small" "sentence" "2" "Another" "tiny"
[8] "sentence"
作为网络数据抓取中三种信息提取方式之一(另外两种分别是XPath表达式和CSS选择器),正则表达式最为底层,也是最难掌握的一种语法,初学时不应追求复杂的正则表达式形式,能做到简单有效的对文本模式进行匹配即可。
参考资料:
Automated Data Collection with R
R语言自动数据采集- 本文固定链接: https://maimengkong.com/learn/1023.html
- 转载请注明: : 萌小白 2022年6月23日 于 卖萌控的博客 发表
- 百度已收录
