在字符串处理中经常会使用到正则表达式,例如从HTML源码中或事件日志中获取目标数据,一般可以通过正则表达式完成任务。在我看来,所谓正则表达式就是根据字符串中的规律书写的一种表达式,关键点是发现规律。根据我的工作应用场景,字符串处理中最为常见的四种手段有“拆、替、抽、取”,具体来讲就是:
拆:将字符串按照某个分隔符切割开来
例如,邮箱“lsxxx2011@163.com”,我想把邮箱的地址和域名拆分开来,就需要按照“@”符,对字符串进行拆分。
替:将字符串中的某段内容替换成别的字符串
例如,从网站抓取下来的数据往往是这样显示的:带千分位符的数据“12,345,678”或带百分号的数据“84.23%”。这样的数据其实是字符型的数值,无法进行四则运算,这就需要把千分位符或百分位符剔除(即用空字符串代替)。
抽:将字符串中的某个特定值抽取出来
例如,将QQ聊天记录下载下来是这样的:

如何抽取出每次发言的时间和对应的QQ号两个字段,这就需要字符串的抽取手段。
取:将字符串中的某段连续子集取出来
例如,将身份证号(123456198907177890)中的出生日期取出来,而出生日期正好是身份证号中某段连续的子集。
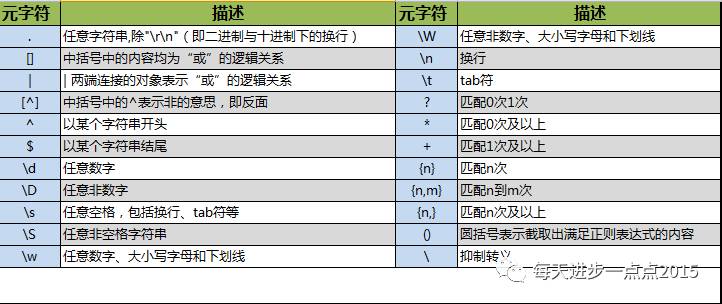
介绍完上面常用的4种字符串处理方法,接下来我们来讲讲正则表达式都有哪些?常用的正则含义如下图所示,字符串的规律(正则表达式)可以通过这些元字符的组合体现。
最后我们来看看,R语言是如何结合正则表达式完成上面所讲的4种字符串处理方法,这里我们强烈推荐stringr包,里面提供了“拆、替、抽、取”的专用函数,个人觉得远比R自带的grep、regexp、strsplit、sub等函数好用。
拆:str_split
str_split(string, pattern, n = Inf, simplify = FALSE)
string:指定需要处理的字符串向量
pattern:分隔符,可以是复杂的正则表达式
n:指定切割的份数,默认所有符合条件的字符串都会被拆分开来
simplify:是否返回字符串矩阵,默认以列表的形式返回
例子:
# 用@或-将字符串切割开来
str_split(c('lsxxx2011@163.com','0511-87208801'), '[@-]')
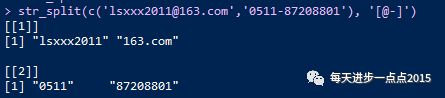
以列表的形式返回结果。
例子:
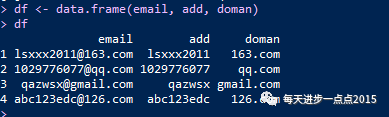
例如数据表中有一列邮箱字段,如何把地址和域名两部分拆分开来存储到新的两列中?
email <- c('lsxxx2011@163.com','1029776077@qq.com',
'qazwsx@gmail.com','abc123edc@126.com')
# 结合sapply函数获得@分隔符前面和后面的内容
add <- sapply(str_split(email,'@'),'[',1)
doman <- sapply(str_split(email,'@'),'[',2)
df <- data.frame(email, add, doman)
df
替:str_replace与str_replace_all
str_replace(string, pattern, replacement)
str_replace_all(string, pattern, replacement)
string:字符串向量
pattern:被替换的子字符串,可以是复杂的正则表达式
replacement:用来替换的字符串
两个函数的区别在于,前面函数只替换首次满足条件的子字符串,后面的函数可以替换所有满足条件的子字符串。
例子:
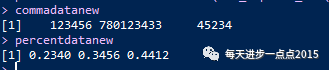
#将含有千分位符或百分位符的数据转换为数值型数据
commadata <- c('123,456','780,123,433','45,234')
percentdata <- c('23.4%','34.56','44.12%')
commadatanew <- as.numeric(str_replace_all(commadata, ',', ''))
percentdatanew <- as.numeric(str_replace_all(percentdata, '%', ''))/100
commadatanew
percentdatanew
抽:str_extract和str_extract_all
str_extract(string, pattern)
str_extract_all(string, pattern, simplify = FALSE)
string:字符串向量
pattern:抽取出满足条件的子字符串,往往使用正则表达式
simplify:是否返回字符串矩阵,默认以列表的形式返回
两个函数的区别在于,前面函数只抽取出首次满足条件的子字符串,后面的函数可以抽取出所有满足条件的子字符串。当前面的函数没有匹配到抽取的结果,则返回NA,而后面的函数在没有匹配到抽取的结果时返回character(0)。
例子:
# 抽取出字符串中的日期和流量值
s <- c('date:2017-04-14,pv:223453','date:2017-04-15,pv:228115',
'date:2017-04-16,pv:201233','date:2017-04-17,pv:324123')
date <- str_extract_all(s, '[0-9]{4}-[0-9]{2}-[0-9]{2}')
pv <- str_extract_all(s, 'pv:([0-9]*)')
unlist(date)
unlist(pv)

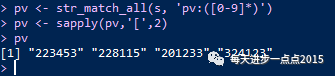
结果中的pv两竟然还是包含'pv:'字符串,实际上我用了圆括号,只想取出pv对于的数值,却没有起作用。难道R中圆括号不起作用吗?这里还需要跟大家结束另一个"抽"的函数:str_match_all。
str_match(string, pattern)
str_match_all(string, pattern)
函数参数的含义同str_extract。
pv <- str_match_all(s, 'pv:([0-9]*)')
pv <- sapply(pv,'[',2)
pv
取:str_sub
str_sub(string, start = 1L, end = -1L)
string:字符串向量
start:指定获取子字符串的起始位置
end:指定获取子字符串的终止位置
注意:如果start或end为负整数时,则从字符串的最后一个字符向前查询
例子:
# 获取身份证中的出生年月(注意18位长度和15位长度)
s <- c('123456198907177890','112318890717042','112233199001014455')
birthday <- ifelse(nchar(s) == 18, str_sub(s, 7,14),
paste0(19,str_sub(s,7,12)))
birthday

例子:
# 获取手机号的末尾4位(负整数参数)
s <- c('13611235678','13912343344','17888886666')
tail4 <- str_sub(s, -4)

讲到这里,我们本期的内容基本结束,重点是如何组合那些正则元字符,来满足你说需要的规律。有兴趣的朋友可以作进一步的交流,使我们在处理字符串数据时能够得心应手。
每天进步一点点2015
- 本文固定链接: https://maimengkong.com/kyjc/1024.html
- 转载请注明: : 萌小白 2022年6月23日 于 卖萌控的博客 发表
- 百度已收录
