一、 工作空间
工作空间,意味着,所有R的程序文件、数据集、其他相关资料都保存在某一个文件夹下面,十分方便提取。
在一个R语言程序结束后,工作空间可以保存它的映像,在下次启动R时,该工作空间,包括历史代码就会自动重新加,非常方便。但没次使用的包需要重新加载。
1.设置工作空间
方法一,采用setwd()语句,设置工作空间,设置的文件夹需事先在硬盘中建立,R语言无法创建新的文件夹。
setwd("C:/Users/Administrator/Desktop/ R data") #引号要英文格式
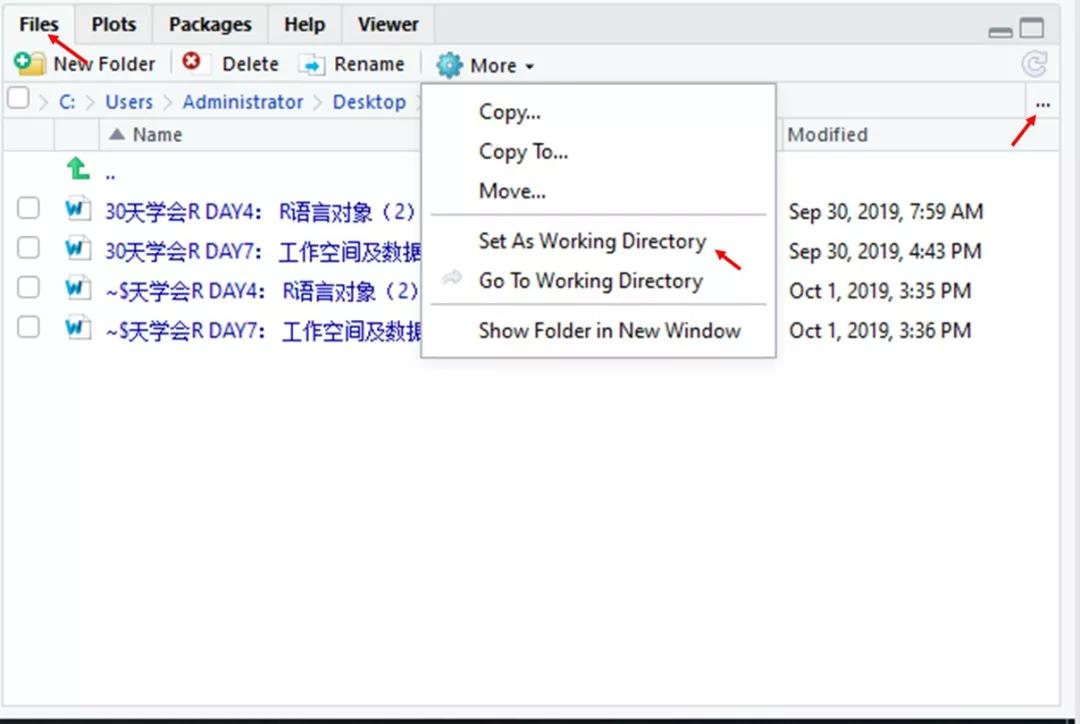
方法二,“其它工具”窗口操作,将file显示路径直接设置成工作空间
在Rstudio右下方的界面中:文件——more——set as working directory。
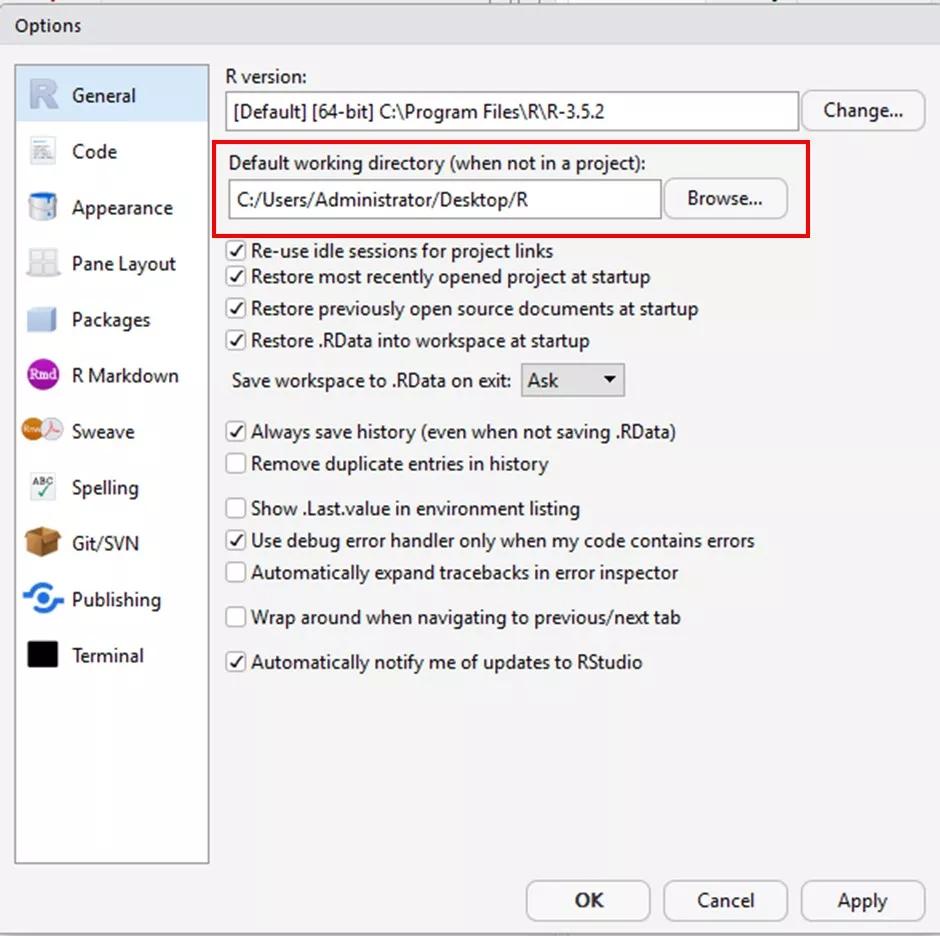
方法三,在菜单栏中操作,永久设置工作空间,每次打开R软件就默认为工作空间:
Tools——Global options中的Default working directory中设置工作空间
2.查看工作空间
通过getwd()获取工作空间的地址,查看目前的工作空间在哪里
getwd()
[1] "C:/Users/Administrator/Desktop/ R data" #显示工作空间
二、数据集导入
在Rstudio 可以导入后缀是txt, csv, xls, sav等格式的文件,但不同的格式所用的包不同,需要进行加载。
方法一,利用R语言命令导入,包括read.table, read.csv, read xls, read.spss
read.table(file=“文件名”,header=TRUE) 读取文本数据,header第一行是否读取为标题,默认为TRUE
elder1<-read.table(file="elder1",header = TRUE) #读取文本文件,第一行为标题
read.csv(file, header = TRUE,rowname=1) 最常用的读取文件,建议转化为csv格式后读取, header第一行是否读取为标题,默认为TRUE ;rowname是否设置横标目,默认不设置。
elder1<-read.csv("elder1.csv") #文件要加后缀名
读取excel需要加载“readxl”包,读取spss数据需要加载“haven”包
library(readxl)
elder1<- read_excel("elder1.xlsx") #导入excel数据
library(haven)
logistic<- read_sav("elder1.sav") #导入spss数据
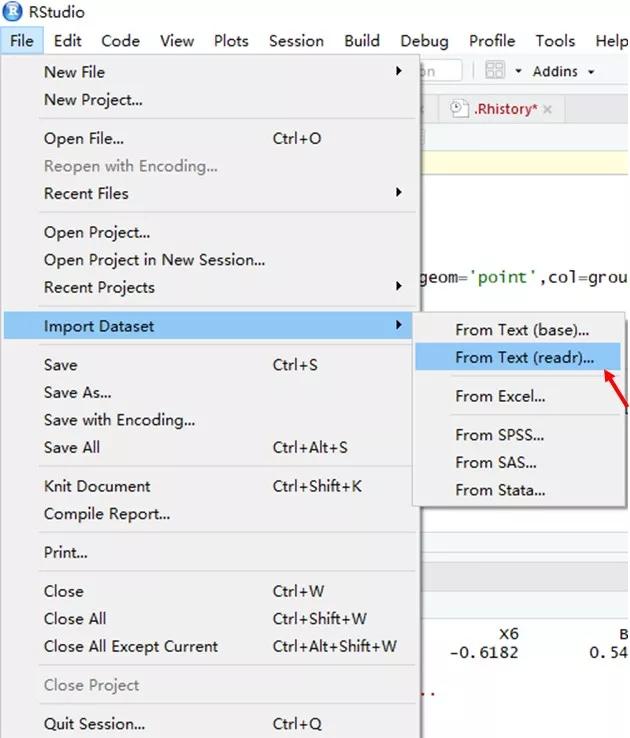
方法二,利用Rstudio菜单导入:file-import dataset,需要选择正确的导入文件,From Text(reader)读取csv文件。
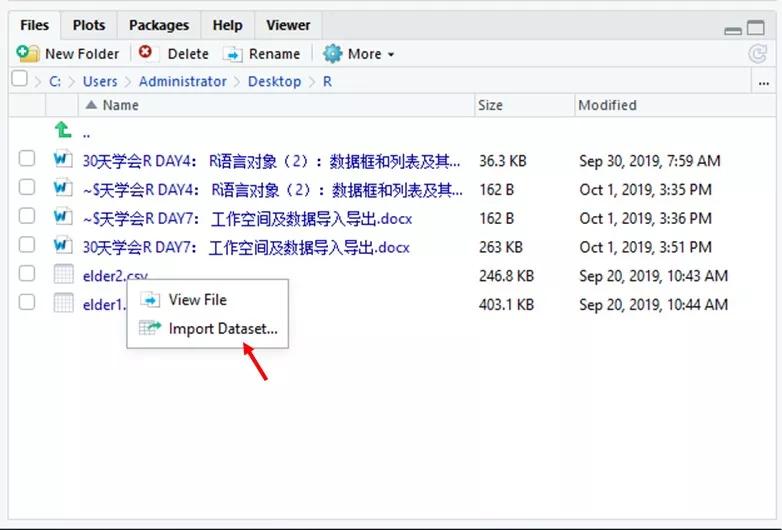
方法三,右下角“其它工具窗口”找到数据存的文件夹,单击数据文件,import dataset
三、.数据集的导出
将R里的数据框形成新的文件导出,常用方式是write.csv格式
write.csv(x, file = "", na = "NA", row.names = TRUE,col.names = TRUE, row.names = TRUE,) x指的数据框,file = ""保存的文件名,na = “NA”缺失值导出方式,col.names = TRUE ,第一行名导出,默认导出;row.names = TRUE,第一列名导出,默认导出。
write.csv(elder1, file = "eldernew.csv", row.names = FALSE, na = "NA") #导出名为eldernew文件名的csv文件,行名不读取,缺失记“NA”
四、数据集的基本描述和总结
这部分函数主要是对数据集变量名、变量类型、变量数、观察单位数、均数、中位数、四分位间距、标准差、百分比进行描述。
str(elder1) #显示变量内容结果,包括变量名,变量类型,变量值等
head(elder1) # 显示数据集前6行
head(elder1,10) #自定义显示的行数,比如10行
class(elder1)# 可以鉴定数据集是数据框、列表还是矩阵等
class(elder1$weight) # 可以鉴定数据某一个变量是数值、字符串、还是分类变量等
names(elder1) # 显示数据集的各个变量名
ncol(elder1) #显示列数
nrow(elder1) # 显示行数
colnames(elder1) #列名 也是所有的变量名
dim(elder1) #数据集有几行几列
length(elder1$weight) #某个变量有多少个记录,length(elder1)有多少列
summary(elder1) # 数值计算每一列均数、中位数、百分位数、最大最小值,字符串列出计数,一般用于数值型的变量
table(elder2$sex) #对分类变量分组汇总计数,table对一列进行分组
table(elder2$sex, elder2$marriage) #交叉表制作,根据两个变量形成交叉表
table(elder2$sex,useNA=”ifany”) #对缺失值也要汇总计数,useNA可定义三种,no不计数,不描述,ifany有的计数,描述,always描述
colSums(elder1[,c(5,6)]) ##多列计算时用col,计算5、6列个列总计
colMeans(elder1[,c("V6","V8")]) ##计算v6、v8两个变量的平均值
DAY6的内容就介绍到这里!
转自:医学论文与统计分析- 本文固定链接: https://maimengkong.com/kyjc/966.html
- 转载请注明: : 萌小白 2022年6月4日 于 卖萌控的博客 发表
- 百度已收录
