当我们只需要对数据集中的部分数据进行分析,就需要用的数据的提取,这是日常最常用的命令。
开始之前,我们先读入elder1这个文件
elder1<-read.csv("elder1.csv")
dim(elder1) #显示几行几列
[1] 5846 12 显示5846行,12列
一、 数据提取
1. 子集的提取(行的提取)
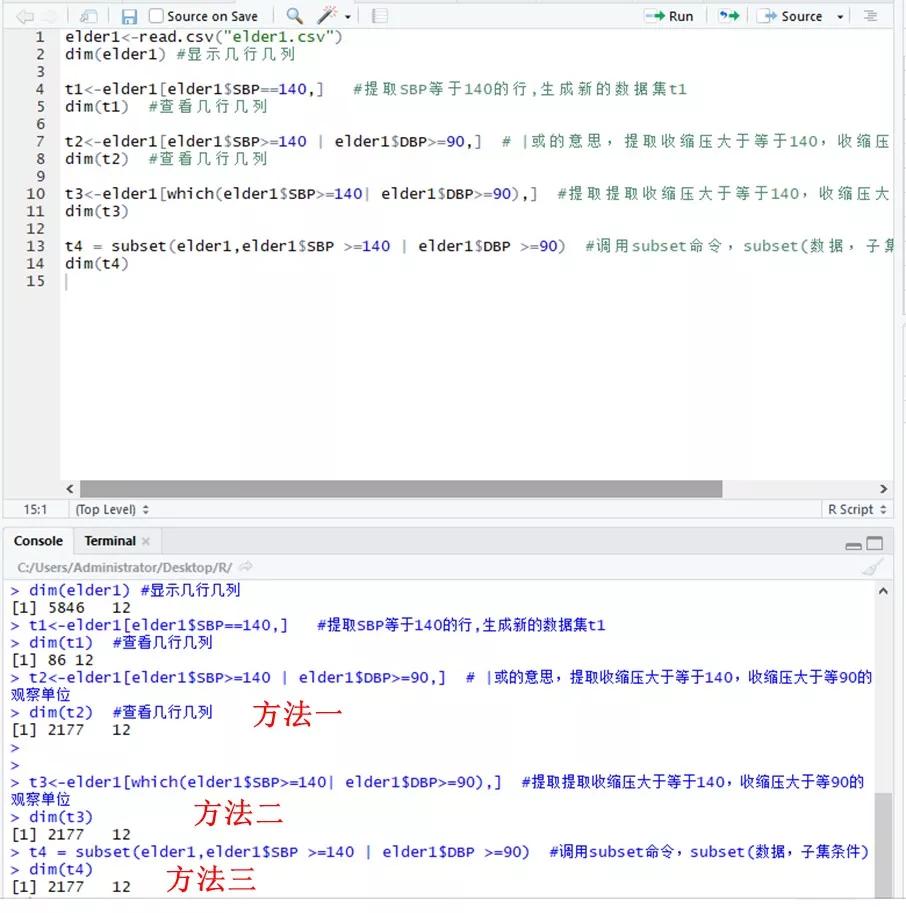
数据集子集提取方式有很多,这里介绍几种常用的方法
数据集[数据集$变量==条件,] 行列提取方式,逗号前提取行,逗号后提取列
数据集[which(条件),] 行列提取方式,加入which语句
subset(数据集,条件) subset语句
方法一 数据集[数据集$变量==条件,] 通过行列提取
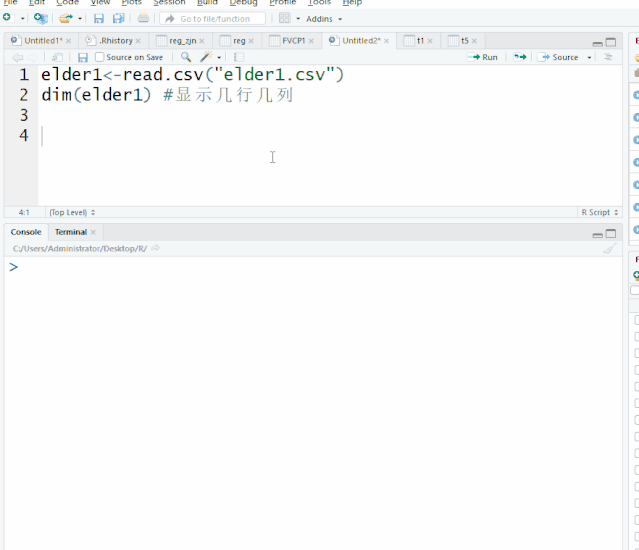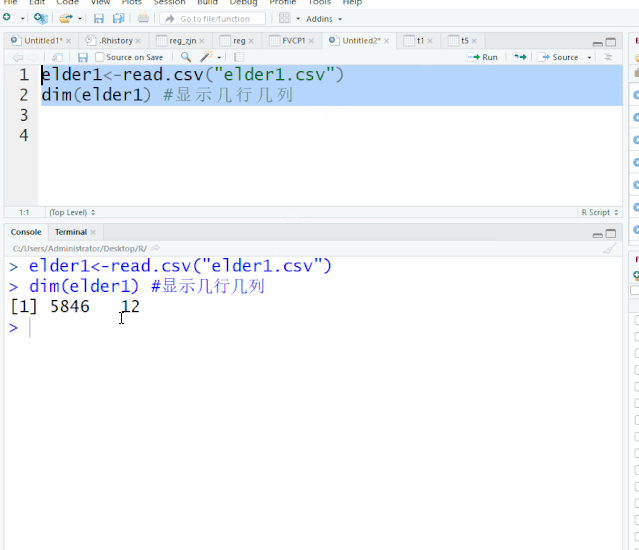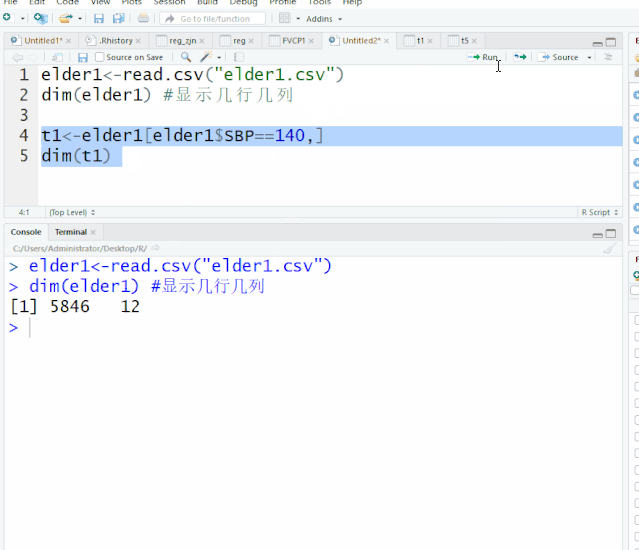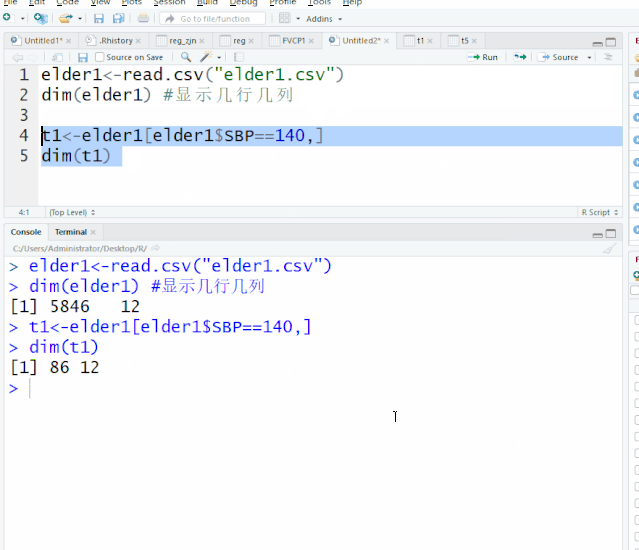
t1<-elder1[elder1$SBP==140,] #提取SBP等于140的行,生成新的数据集t1
dim(t1) #查看几行几列
[1] 86 12 收缩压等于140的观察单位86个
t2<-elder1[elder1$SBP>=140 | elder1$DBP>=90,] # |或的意思,提取收缩压大于等于140,收缩压大于等90的观察单位
dim(t2)
[1] 2177 12
方法二 数据集[which(条件),] 利用which限定条件
t3<-elder1[which(elder1$SBP>=140| elder1$DBP>=90),] #提取提取收缩压大于等于140,收缩压大于等90的观察单位
dim(t3)
[1] 2177 12
方法三 subset(数据集,条件) subset语句
t4 = subset(elder1,elder1$SBP >=140 | elder1$DBP >=90) #调用subset语句
dim(t4)
[1] 2177 12
2. 数据集变量提取
数据集[“变量名”] 通过列名,提取列
可用c(“”,””)提取多个变量,也可用%in% 提取多个变量
方法一 数据集[“变量名”] 通过列名提取单个变量
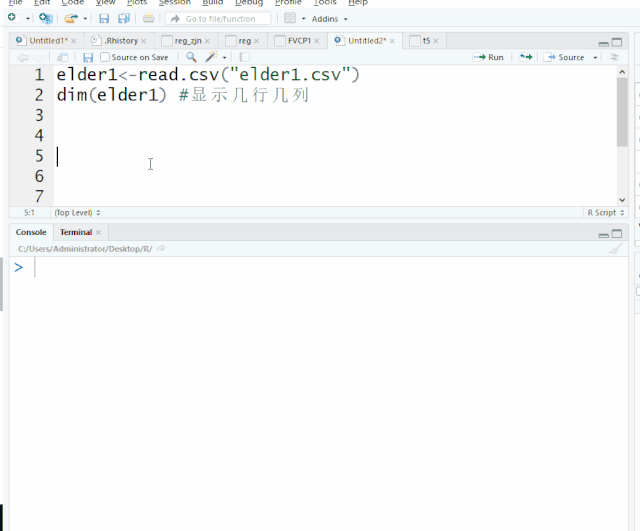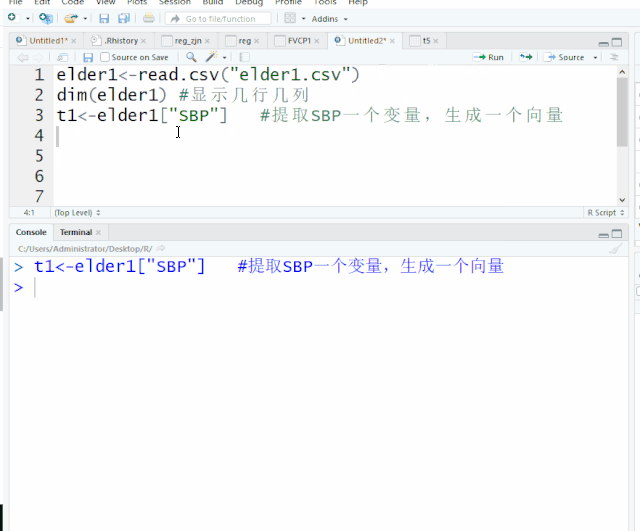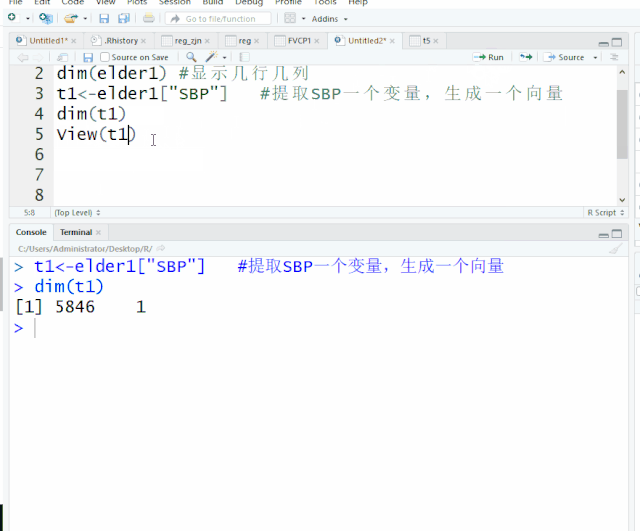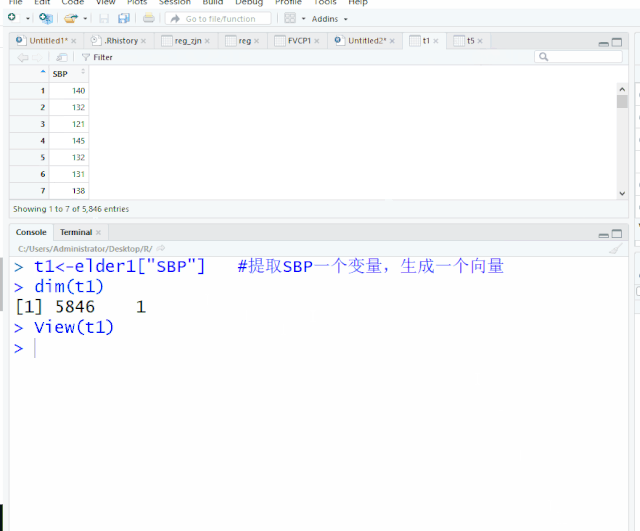
t1<-elder1["SBP"] #提取SBP一个变量,生成一个向量
view(t1) #查看t1向量
方法二 数据集[c(“变量名1”,“变量名2”)] 通过向量提取多个变量
t2 <- elder1[c("SBP","DBP")] #提取SBP,DBP两个变量
view(t2) #查看t2数据集
t3 <- elder1[c(8,9)] #如果知道被选取的变量是第几列情况下,可直接输入列数
view(t3)
事先设定向量
z1 <- c("SBP","DBP") #事先设定向量
t4 <- elder1[z1] #如果elder1里没有z1中的变量,就会出现错误
dim(t4)
[1] 5846 2 5846行 2列
事先匹配变量名 %in%语句
z2<- names(elder1) %in% c("SBP","sex") # 匹配elder1数据集和向量c中的变量,优点在于变量名会自动匹配,输错了也能运行
t5 <- elder1[z2] ###选出z2中匹配的变量
dim(t5)
[1] 5846 1 只匹配了SBP变量
二、变量名剔除
数据集[,-列数] 剔除选中的列数
数据集【!“逻辑符”】 剔除逻辑符号是TRUE的列
方法一 数据集[,-列数] 根据列数进行删除,有时候知道变量在哪一列比较麻烦
t1<-elder1[,-2] #删除第二列,需要知道要删除的变量在第几列
dim(t1)
[1] 5846 11
t2<-elder1[,-c(2,3)] #删除第二、第三列
dim(t2)
[1] 5846 10
方法二 数据集【!“逻辑符”】,想要根据变量名进行,需要用到!语句,利用逻辑符来剔除
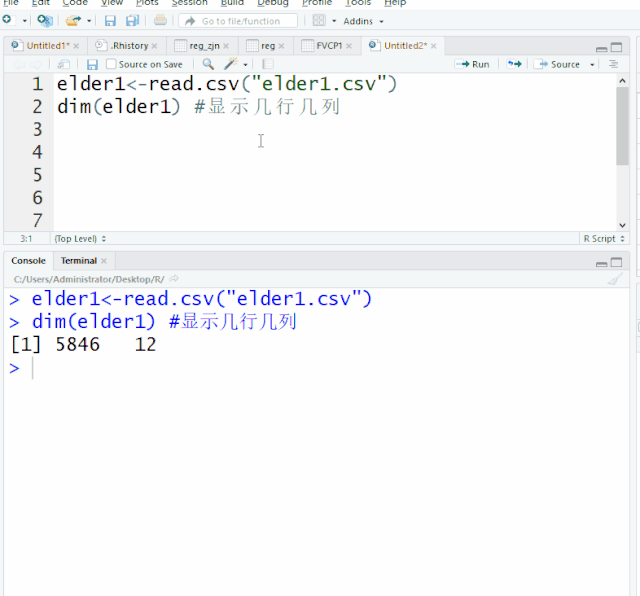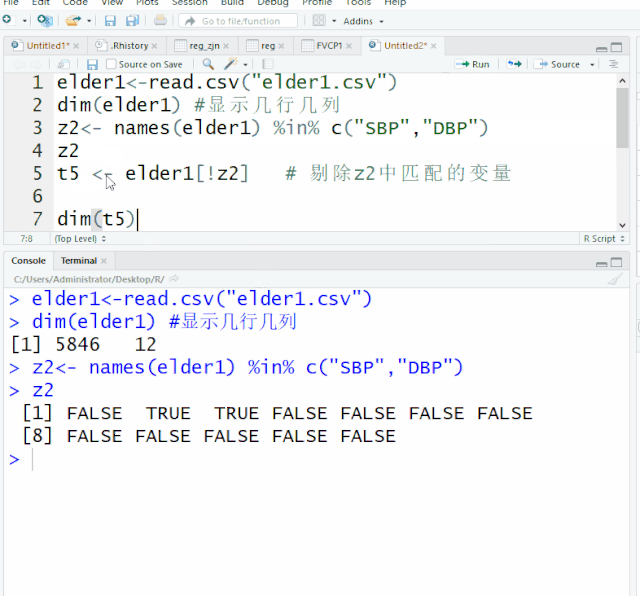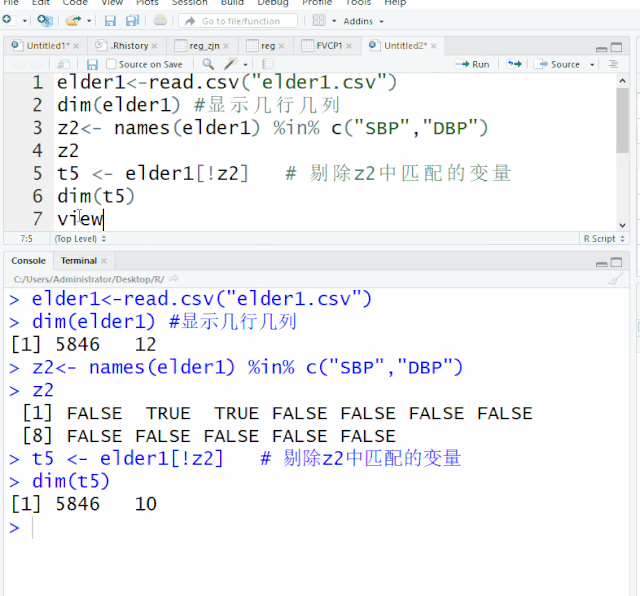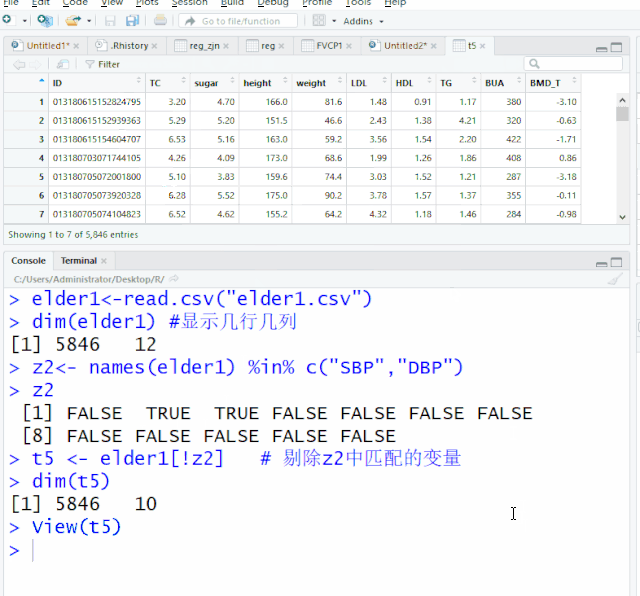
z2<- names(elder1) %in% c("SBP","DBP") #事先匹配变量名 %in%语句
z2
[1] FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE !可将TRUE列剔除
t5 <- elder1[!z2] # 剔除z2中匹配的变量
dim(t5)
[1] 5846 10 t5数据集中列数为10
view(t5)
DAY7的内容就介绍到这里!
转自:医学论文与统计分析
- 本文固定链接: https://maimengkong.com/kyjc/967.html
- 转载请注明: : 萌小白 2022年6月4日 于 卖萌控的博客 发表
- 百度已收录
