文| R扫地僧
1910字 | 6分钟阅读
大家好,我是一名数据分析师,目前在一家互联网公司,做私域业务相关的数据分析工作。

我经常会用R语言解决数据分析工作系列问题。在此,我分享下做数据分析工作常用的8个R包,也欢迎朋友们补充和分享自己常用的R包。
1 dplyr包
我用dplyr包做数据的整理工作,包括数据的选择(业务所需的行与列),变量的新增,数据的集成(常用的内连接和左连接),数据的聚合运算(描述性统计常用指标,求和、最大值、最小值、均值、中位数、个数、分位数),数据的清洗工作等。我在前面的文章,介绍了dplyr包一些用法,系列文章如下:
我编写的R语言程式90%都用到这个包。众所周知,做数据分析工作之前,数据的准备和加工,需要花费我们50%到70%的时间和精力,因此,掌握和熟练使用这个dplyr包,可更有效地完成数据整理的工作。

2 ggplot2包
我用ggplot2包做数据可视化分析的工作。 数据可视化,通过图形的方式,帮助我们理解数据,洞察数据以及表达数据结果和讲好数据故事。ggplot2包,基于图形语法和分层的思想,高效地实现一系列图形。我们可以从 变量的个数、变量的类型以及变量之间的关系三个方面,确定需要创建什么类型的图形。我在这里推荐几本数据可视化的优秀书籍,这些书籍里面都有关于ggplot2包学习和应用的介绍。
数据可视化好书集合

3 stringr包
我用stringr包处理字符串类型相关的数据,比方说,字符串替换、子串的查询,字符的计数,字符串的修改等系列操作。实际工作中,字符串类型的数据,经常会遇到。很多时候,原始数据集,都要做清洗工作,才能被用于后续操作,比方说重编码,聚合汇总等。

4 data.table包
data.table包,一个增强版的数据框结构,可以更高效地存储和处理数据集。对于这个包,我主要用它来做数据的存储以及数据结构之间的转换操作。这个包详细介绍和使用,可以查阅这个链接:
https://rdatatable.gitlab.io/data.table/
5 tidyr包
我用tidyr包来做 数据重塑工作,主要包括:1)把宽数据转换成长数据;2)把长数据转换成宽数据。这个时候,我们需要根据实际情况,选择合适的操作。tidyr包,用 spread函数把长数据转换为宽数据; gather函数把宽数据转换为长数据。
6 caret包
我常用caret包来做有监督机器学习的任务,以及数据集的划分和数据集预处理的相关操作。这个R包对于做有监督的机器学习任务,提供了一个统一编写程式的框架。当然了,你使用这个包做随机森林的任务,前提是需要安装和加载randomForest包。关于这个R包的详细用法,可以查阅这个链接:
http://topepo.github.io/caret/index.html
7 cluster包和factoextra包
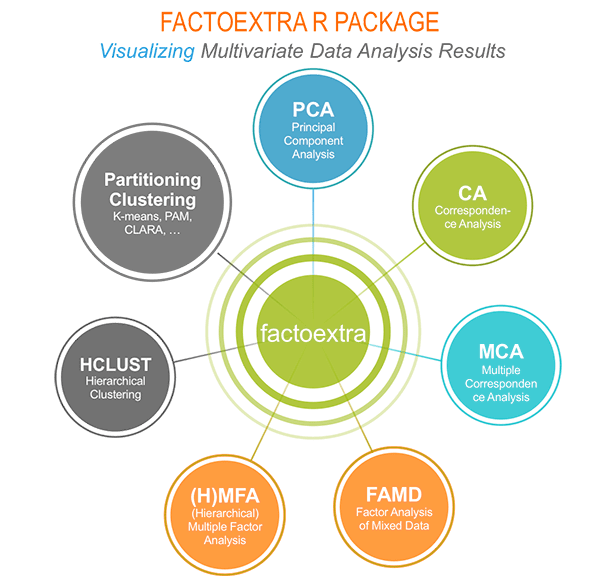
我有时会用聚类分析的方法,去做 分群或者分组的事情。这种技术,可以让组内相似性最大,组间差异性最大。我常用的聚类分析方法,一种是划分方式聚类,一种是分层方式的聚类。为了更好地地解读聚类的结果,对聚类效果的可视化,是一种很好地手段。所以,我会用到 cluster包和factoextra包。这两个包组合,可以实现聚类分析以及聚类结果的可视化分析。 factoextra包除了做聚类分析结果可视化,还可以做其它事情,如下图所示:
8 arules包和arulesViz包
关联分析和规则挖掘,也是我在实际工作,经常会用到的方法。对于能够表示或者转化成事务型数据格式的业务场景,我们都可以尝试使用关联分析的方法去发觉数据洞见,以指导业务做有效行动。我用 arules包做频繁项挖掘和关联规则挖掘,使用 arulesViz包对关联规则做可视化分析。
除了使用上述这些R包,在实际工作中,也会根据具体的业务问题和实际任务,使用其它R包。关于R包的学习和使用,首先,会查看一下这个R包应用实例;其次,把相关代码迁移到自己的手头数据上,第三,在自己实际数据项目中,进一步加深对R包的理解。
朋友们,你们在实际工作中,常用那些R包,请留言。
- 本文固定链接: https://maimengkong.com/kyjc/786.html
- 转载请注明: : 萌小白 2021年10月9日 于 卖萌控的博客 发表
- 百度已收录
