1、基础描述分析
历史上有这样一幅著名的图,它出自1854年的克里米亚战场之中,一名叫南丁格尔的护士利用一幅扇状的玫瑰饼图展示了她所管理的野战医院里不同季节中死于不同病因的病人数变化(见图1),直观地让英国政府看到:每年死于感染的士兵数(即蓝色区域)比死于战场(红色区域)和其他原因(黑色区域)的要多得多,这才终于使得政府开始制定措施改善战地士兵的卫生条件,降低了士兵的死亡率。因此这幅图被称为拯救生命的图表,这也是较早使用统计图形传达信息的例子。
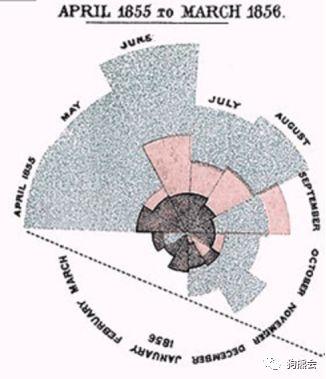
图1 南丁格尔的玫瑰饼图
本章将为大家讲述如何画基本统计图形,即对数据的描述分析。描述分析在整个数据分析过程中占据着重要地位,建模前,它是观察数据、发现问题、识别异常与规律的有力武器;建模后,它是总结规律、表现结论、传递信息的生动方式。因此了解和学习基本的作图方法,无疑会对我们的数据分析大有裨益。下面从R语言中的base包入手,来介绍统计基本图表的实现。
统计的基本图表并不多,简单来说,柱箱点、折直饼就是我们最常用的图表类型,具体有柱状图、箱线图、散点图、折线图、直方图和饼图。它们是针对不同变量类型、不同变量个数展现时可能用到的工具。所谓“工具为用途而生”,用好工具,首先要知道为谁画图,简单来说,问自己两个问题:(1)描述一个变量还是两个变量(多个变量展示通常都是前面基础图的组合,不恰当地使用立体图可能在表面酷炫之下使信息传达失真)?(2)描述的变量是什么类型,即定性变量还是定量变量?回答了这两个问题,就可以参考下面的介绍来选用图形了。接下来介绍各种图使用的场景及其R语言实现[本案例数据来自狗熊会公众号推文《菜鸟专栏|网络小说排行榜分析》(进入狗熊会公众号,输入关键词“网络小说”阅读原文)。]。
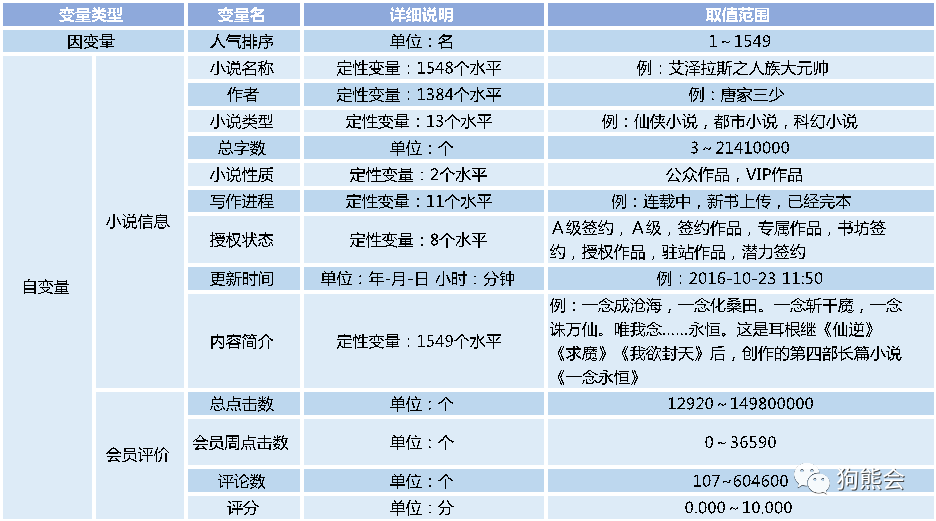
本案例数据的主要变量如表1所示,下面结合这个数据讲解R中的基础作图。
表1 小说数据变量说明
1. 单变量作图
(1)一个定性变量。所谓定性变量,就是性别、国籍这类描述一个事物质的特性的变量,其取值只能是离散的,比如男、女,中国、英国等。描述该类型变量的图形有两种:柱状图和饼图。
1)柱状图。柱状图适合展示一个定性变量的频数分布,也可用来观察不同类别样本的分布。R中主要采用barplot函数完成,它的使用方式是barplot(height, names.arg),其中height是柱子的高度,names.arg是柱子的名称。例如在小说数据中,小说类型就是一个有不同取值的定性变量,如果想看数据中排名前五的小说类型的频数分布,便可以画一个柱状图(见图2)。

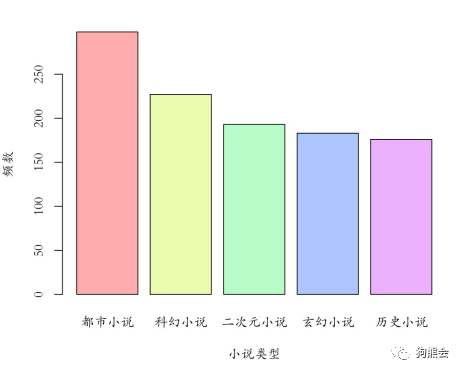
图2 不同类型小说分布柱状图
图2显示,平时大家最爱读的首先是都市小说,其次是科幻小说,最后是二次元、玄幻和历史小说,后三者的阅读频数相差不大。
另外,从代码演示可以看出,barplot函数的基本参数只需要每个类别的数量,也就是说定义不同柱子高度的向量,后面的常用参数包括names.arg可定义每个柱子的名字,即分类变量的类别名称,col可以用来定义柱子的颜色,main可以用来定义图标题,等等。需要特别提醒的是:在定义颜色时采用了rainbow函数,它可以生成漂亮的彩虹色,还可以通过alpha参数来调节透明度,让显示出来的颜色不那么突兀。图2中的柱状图看似简单,但画不好也很容易突兀难看[为避免画丑图,可阅读《丑图百讲|这根柱子,你咋不上天呢?(上)》(进入狗熊会公众号,输入关键词“这根柱子(上)”阅读原文)。]。
2)饼图。柱状图能用“高度”展现每个类别的数量多少,那还有没有其他展现数量对比的手段呢?有,饼图就是另外一个常用选择。
在R中画饼图的核心函数是pie,其使用方法是pie(numerical vector, labels),也就是要传入画饼图的数字向量(也就是各类别的频数)以及每块小饼的标签,其他诸如定义颜色、标题等的参数与barplot用法相同。简单来说,任意定义一个数值向量,就可以马上为它画张饼,来展示各自的比例(见图3)。
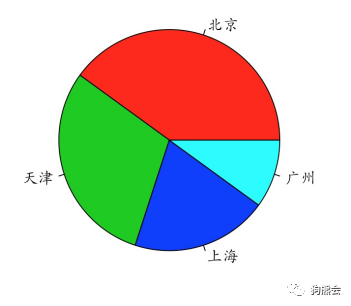
图3 熊粉成员分布饼图
当然,这样简单画出来的饼图可能并不满足我们展示的需求。下面结合小说数据,来看看如何让饼图美起来。这里我们新生成一列“小说类别”的变量来辅助说明。

这里展示了画饼图所需要的常用技巧:合并小类,计算百分比以及如何展示各块饼的标签。另外,此处特别推荐另一组颜色设置函数:heat.colors,它类似于前面讲到的rainbow,是一套“配色模板”。heat.colors可以产生类红色的一组邻近色,很适合在渐变色的场景中,而且同样可以设置透明度(见图4)。
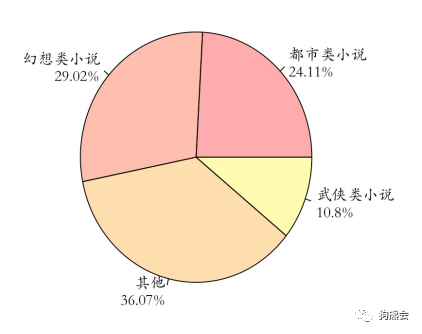
图4 小说类别频数分布饼图
当然,并不是任何一个定性变量都适合画饼图展示,什么样的定性变量适合画饼图,怎么画图能够和谐摆布各种标签信息呢?可以参考《丑图百讲|水哥,喂公子吃饼!》进一步学习[进入狗熊会公众号,输入关键词“喂公子吃饼”阅读原文]。
(2)单个定量变量。所谓定量变量,就是可以取连续数值的变量,比如年龄,收入等。常见的变量取值可以是不同对象在该变量上的取值,即横截面数据,如电视剧《人民的名义》里所有男演员的身高;也可以是一个变量在不同时期的取值,即时间序列数据,比如主角侯亮平在不同时期的收入变化。针对这两种变量,有哪些合适的图来描述呢?
1)直方图。对于横截面数据来说,最重要的可能就是它的分布了。分布这个概念在统计学中再重要不过,直方图能够直观地展现数据的分布形态及异常值,是清洗和描述数据的小帮手[希望进一步了解直方图的读者请阅读《丑图百讲|最受统计学家欢迎的统计图居然是?》,进入狗熊会公众号,输入关键词“最受统计学家欢迎的统计图”,阅读原文。]。
R语言中画直方图的命令是hist,直接使用hist(x)可以简单地画出变量x的直方图。当然,如果想展示更全面的信息,就需要设置hist里面的其他参数,比如xlab可以用来设置直方图的横坐标题目,ylab可以用来设置直方图的纵坐标题目,breaks可用来设置直方图的组数或分割点。熟悉统计学的读者应该知道,设定不同的组数能够展示数据的不同细节,比如将小说字数这个变量取对数后做不同的分组,显示效果如图5所示。

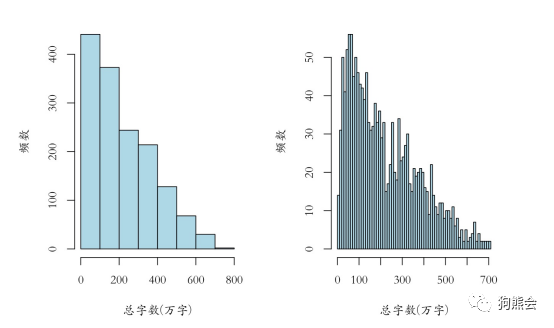
图5 不同组距下的小说字数对比直方图
通过对比观察,可以看出,图5中左图简单直观,可看出小说的数量随着其字数增多而逐渐减少,大部分小说在200万字以内;而右图则展示了更多的细节,不仅可以观察到总字数在100万左右的小说最多,而且还可以看到200万之后还有几个小高峰出现。可见组数越多,可以获取的信息就越丰富。
2)折线图。针对时间序列数据,通常想观察的是该指标随时间变化的趋势,那么折线图就是可以帮助“观趋势看走向”的有效工具。
在R中画折线图很简单,如果数据已经是R中的某种数据格式(比如tz),那么直接采用plot(x)即可(见图6)。

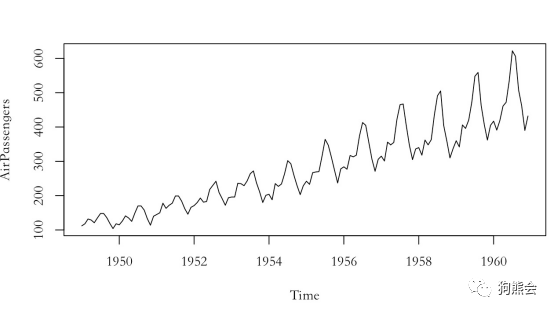
图6 乘客时间序列图
而如果拿到的数据仅仅是一个普通向量,又该如何将其变成可用于画图及后续时间序列分析的数据格式呢?如果数据是年、月或者季度数据,可以采用tz函数直接加以转化;如果数据是天数据或者不等间隔的时序数据,可以选择另外一个包zoo来生成。下面以电视剧《人民的名义》的百度搜索指数为例示范后一种情况。
首先,生成时间序列数据仅需两步:①设定好时间标签(如例中的date);②使用zoo函数将时间标签及对应的数据“组合”在一起。将数据改为时间序列格式后,直接采用plot函数即可画出折线图(见图7)。

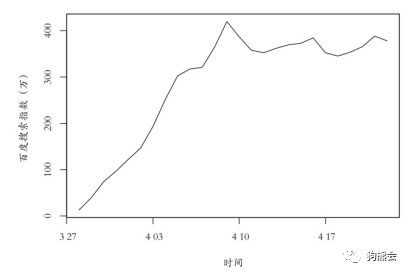
图7 人民的名义搜索指数折线图
如果对横轴显示时间的格式不满意,还可以通过axis函数中的tick和label_name参数来自定义标签,其中tick用来确定横轴标记(即小竖线)的位置,label_name用来设定显示的标签(见图8)。

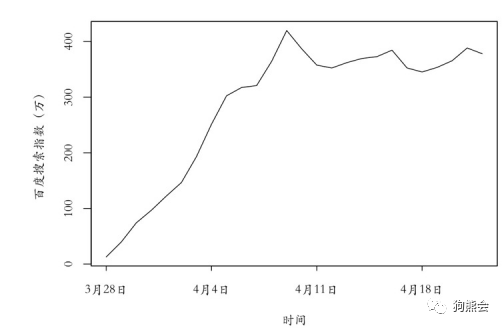
图8 人民的名义搜索指数折线图
当然,别看折线图十分简单,但一不小心也会画得很丑[避免画折线图的丑图,可参阅《丑图百讲|折线图》(进入狗熊会公众号,输入关键词“折线图”阅读原文)。]。
以上就是我们在探索、展示单变量特征时常用图形的R语言实现。当然,一个变量展现的信息往往很有限,有些含义和特征在对比中才愈发明显,下面继续介绍双变量的图形展示。
2. 两变量作图
(1)如何切分画板。在介绍具体的图形前,需要提醒一下,两变量其实就是两个单变量结合在一起,因此理论上可以将两个变量各放一张图,然后摆在一起对着看,怎么让两幅图甚至多幅图摆在一起看呢?这就要用到切分画板功能,即使用par(mfrow=c(a,b))函数将画图的屏幕切分成a行b列个小格子,然后每画一幅图就放在画图板的一个小格子里,整齐划一。
1)定性变量及定量变量。先来探讨如何表现定性变量与定量变量的关系。探索定性变量与定量变量之间的关系是数据分析中很常见的需求,比如比较不同教育水平的收入差异,比较不同地段的房价差异,比较在电视剧里是好人活的集数多还是坏人活的集数多,这些就是在某个分类变量的标准下,比较另一个定量变量的表现。
要达到这个目的的方法有很多,这里特别推荐一种图:分组箱线图,一种好用且直观的工具,能够一目了然地看清两组数据的对比及各自的分布。下面就以一个小例子具体说明用法。
现在市面上的阅读网站经常会推出会员制度来服务不同需求的用户,而我们的数据中就记录了不同的小说是属于VIP作品还是公众作品。那么是公众作品中每部作品的点击数更多,还是VIP作品的点击数更多呢?是公众作品的评论数更多,还是VIP作品的评论数更多呢?如果想探究这些问题,就可以使用分组箱线图来一探究竟(见图9)。
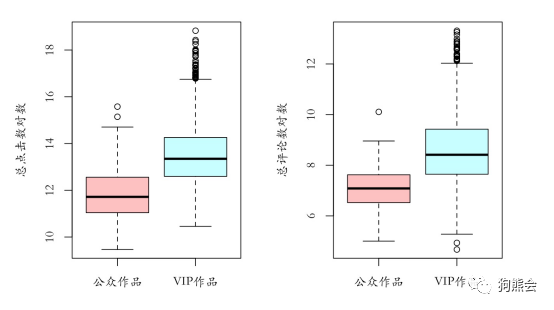
图9 不同类型作品的总点击数、评论数对比箱线图
从图9可以看到,平均看来,每篇VIP作品无论是总点击数还是总评论数都显著比公众作品更多。这个有趣的现象可能出自一种“争取把会费赚回来”的心态,当人们加入会员时,会更倾向于坚持看完这个小说或者再多看几个小说。
画分组箱线图的R语言命令是boxplot,参数可以用“公式形式”表示,即boxplot(y~x),其中y是要对比的定量变量,x是分组变量。这表示将y按照x分组,分别画箱线图[关于箱线图的美图教程可以参见《丑图百讲|箱线图应该怎么用》(进入狗熊会公众号,输入关键词“箱线图怎么用”阅读原文)。]。

2)两个定量变量。如果想探究两个定量变量之间的关系,最常用的就是散点图了,它为我们观察这两变量的相关方向及相关程度提供了直观的阐释。比如图10,经常在教科书中用来解释相关性的就是散点图。
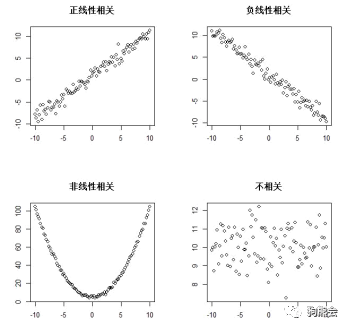
图10 散点图示例
实现散点图命令是plot(x,y),后面可以加设很多有趣的参数来丰富它,比如为图添加标题的main,在图上添加文本的text,设置坐标轴的xlab,ylab等,还可以用col来设置点的颜色,pch设定点的形状,cex设定符号的大小等。
举例来说,比如想看看小说的总点击数和评论数有何关联,便可以画出如图11这样的散点图(为显示清晰,这里选取总评论数在8000以下且总点击数在20w以下的小说数据做示范)。

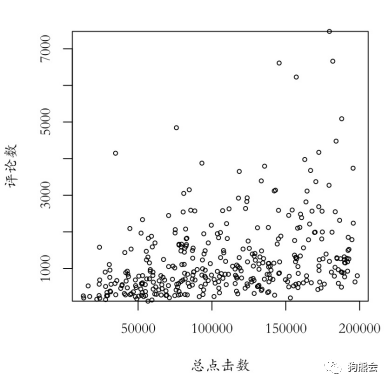
图11 单位面积房价与面积散点图
现实总不如教科书那么美好,从这幅图中模模糊糊可以看出一点正相关的迹象,但相关程度并不高。遇到这种情况,可以考虑把某个连续变量离散化,也就是把它分组,变成定性变量,比如这里将总点击数离散化,再与评论数做箱线图(见图12),这时相关关系就更加明显了。
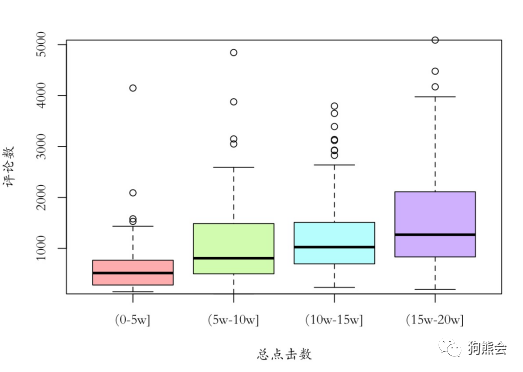
图12 不同点击数的评论数分组箱线图
当然,实践中除了想看两个变量的相关图,可能还想同时看很多变量的相关图,那是不是需要提取出两两变量分别画图呢?当然不用, plot函数早就想好了这一点,plot(data.frame)就可以输出一个散点图矩阵,每个元素都对应着数据框中每两列对应的散点图,如图13所示,这样就可以一次性观察所有变量的相关关系了。
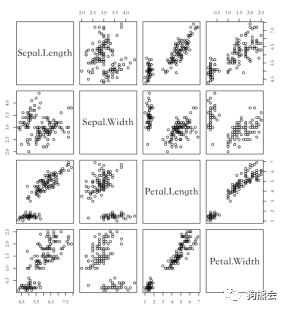
图13 多维散点图示意
3)两个定性变量。前面讲到,定性变量可以用柱状图来表示各个水平的取值,而两个定性变量则可采用柱状图的变形——堆积柱状图和并列(分组)柱状图来表现。此处仍采用小说数据做示范,选择包含2个水平的变量“小说性质”以及包含4个水平的变量“小说类别”作图。首先看两种柱状图的效果(见图14)。
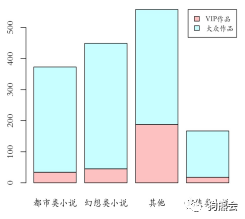
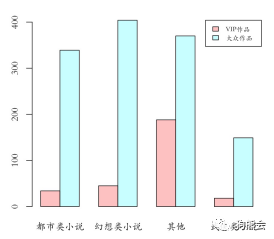
图14 两类柱状图示意
画这种柱状图仍然采用barplot函数,简单点说,只需要在其中添加参数beside,设为T就画出并列柱状图,设为F就画出堆积柱状图,所以图14中的两幅图看起来不同,其实在程序上只不过一个参数的差异。然而真正需要注意的是:画这样的图,需要输入给barplot的数据格式是什么呢?
前面介绍柱状图时已经讲到,画单变量柱状图需要输入一个向量,或者类似向量的数据(比如之前用table函数生成的table类数据),总之就是让R知道每个柱子的高度就行。而如果画堆积或者并列柱状图,又该输入什么格式呢?两个向量?或者一个矩阵?通常会使用矩阵来生成如图14中的复合柱状图。图14中的两个图就是用以下矩阵生成的。

仔细比较图14和上面的矩阵,可以看出,R是按列读数画图。将beside设置为T,R会将列累计在一个大柱子上;将beside设置为F,R会将一列的几个数字(所对应的小柱子)紧紧靠在一起。这就是R的工作方式。
理解了画图的原理,接着思考:如果要把小说性质(即VIP作品/大众作品)放到横轴,让柱子按照小说类别堆积或者并列起来,这图又该怎么画呢,以及怎么把数据整理成上边的矩阵格式呢?这些需求都可以用之前学过的命令解决,留给读者做为思考题。
最后,需要注意的是:这类图由于传达的信息较多,很容易让图看起来杂乱而重点全无。关于什么样的数据适合画这类图,还有什么能让图更美观,可以阅读《丑图百讲|这根柱子,你咋不上天呢?(中)》[进入狗熊会公众号,输入“这根柱子(中)”阅读原文]。
以上是描述分析部分的R语言实现方法,主要讲怎么作画,在实践中还要解决“要画什么”和“怎么画好”的问题。找准了要画什么,就会更快接近数据的规律;领悟了怎么画好,会更清晰地传播你的想法,甚至可能“漂亮得不像实力派”!
2、ggplot2绘图
前边仅仅介绍了R中基础作图系统可以做到的效果,下面介绍可以做到更加出众效果的软件包——ggplot2。
1. ggplot2是什么?
ggplot2是一个由Hadley Wickham于2009年开发的R包,它提供了一个基于Wilkinson所描述的图形语法(并进行一定扩展)的图形系统,目的是提供一个基于语法的、连贯一致的、比较全面的图形生成系统,为用户自己创建各种创新性的数据可视化作品建立基础。官方文档这样描述这个包:它是一个基于图形语法的陈述式绘图系统(“declaratively” creating graphics),你准备好数据,然后告诉ggplot2如何把变量映射到坐标轴,使用什么样的图形元素,其他细节它都会自动帮你打理好。简单说,就是一个帮你画图的R包。
这个包自发布以来就一直热度不减,通过cranlogs包中的cran_top_downloads[关于cran_top_downloads是个什么函数,请参阅《R语千寻|也谈ggplot2》(进入狗熊会公众号,输入关键词“也谈ggplot2”阅读原文)。]可以查看这款包的下载排名(见图15)。
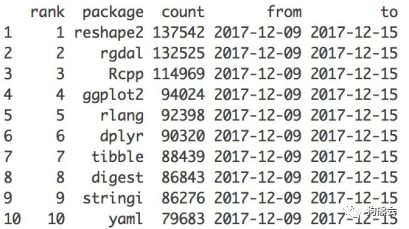
图15 ggplot2 包热度排名
2.为什么要用ggplot2?
为什么要用ggplot2?如果只需要一个理由,那就是很多人用它,是作图酷炫的良心保证。它画出的图与基本款完全不同。且不论ggplot2可以画出各种诸如自画像类的高能图,单从基本图的呈现对比就可初见端倪(见图16和图17)。
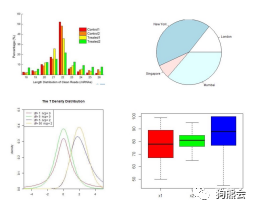
图16 这是基本款
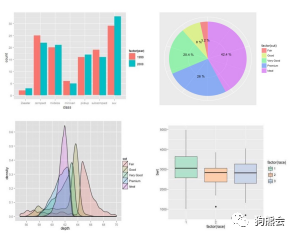
图17 这是升级款
关于ggplot2的设计理念,统计之都创始人谢益辉曾在《ggplot2:数据分析与图形艺术》这本书的中译本序中有过一段精彩论述,他说:“R的基础绘图系统基本就是一个纸笔模型,即一块画布摆在面前,可以在这里画几个点,在那里画几条线,指哪儿画哪儿,但这不是让数据分析者说话的方式,数据分析者不会说这条线用#FE09BE颜色,那个点用三角形状,他们只会说,把图中的线用数据中的职业类型变量上色,或者图中点的形状对应性别变量,这是数据分析者的说话方式,而ggplot2正是以这种方式来表达的。”
接下来介绍ggplot2的画图理念。具体来讲,ggplot2画图的核心是采用了图层叠加的设计方式,它基于一整套完整的图形语法,这套语法能让你使用相似的元素,包括数据、数据所对应的几何对象以及坐标系来绘制不同的图形。图18是出现在《Data Visualization with ggplot2 cheat sheet》的示意图。
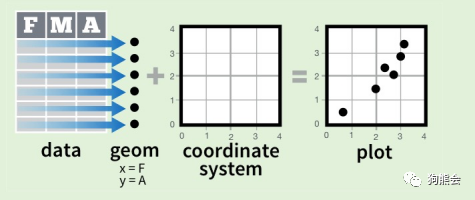
图18 ggplot2图层映射原理
如图18所示,数据集中包含F,M,A三列变量,将F映射到x轴,A映射到y轴,再设置这两列变量映射为图中的点,就画出了一幅两个变量的散点图。
还可以将数据集中的某些属性映射为图中几何对象的属性,比如将变量F映射到点的颜色属性,把变量A映射为点的形状属性,就可以画出如图19的样式了。
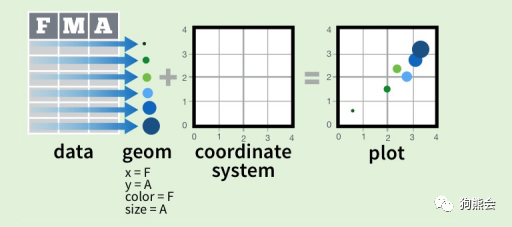
图19 使用ggplot2将变量映射为点的形状和颜色属性
在这个实现过程中,只需要设置把F变量映射为点的颜色,但是无需具体规定映射为什么颜色。这就是ggplot2的另一个小优点:它会帮你把细节自动处理好,比如颜色选择,图例添加,都会以一种默认颜色和位置输出,如果你不满意它的设置,也可以自己修改。不过在最初画图探索阶段,它的这项技能可以帮助有效减少对细节的考虑,专注于图形所表达的内容。
3. 怎么用ggplot2作图?
下面就结合具体的例子来讲解如何用ggplot2绘制基本统计图形。每种图形用在什么场合在本章前面有过详细介绍,下面重点介绍ggplot2的作图语法。
(1)数据集介绍。随着人们物质生活水平的提高,想当年结婚三大件手表、自行车、缝纫机已经发生了翻天覆地的变化(见图20和图21)。

图20 70年代结婚三大件

图21 当代结婚三大件
有人说房子、票子、车子是当今的结婚三大件,虽然略显夸张,不过有一样却是结婚必备信物——钻戒。没有钻戒的求婚还是具有一定的风险的,毕竟,“钻戒”是宣示财富地位的直接表示。电影《色戒》中梁朝伟就用6克拉的鸽子蛋紧紧套住了情人的心;现实生活中,梁朝伟则用整整翻了一倍的12克拉大钻戒虏获了刘嘉玲的芳心,该钻戒也创造了华人女明星婚戒最大颗纪录。
当然,最重不代表最贵,好钻石还与它的切工、纯净度等多方面因素有关。今天我们使用的数据集就是一个关于diamonds(钻石)的数据集,它已经内置于ggplot2包中。此数据集记录了一批钻石的各个物理特征及价格等信息,我们将抽取它的前500条记录以及6个变量作为我们的演示数据,数据的具体情况如表2所示。
表2 diamonds数据变量说明
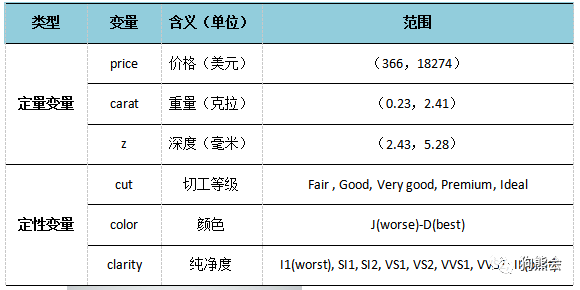

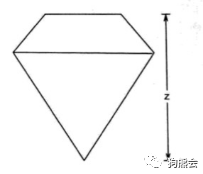
图22 钻石变量示意图
1)为一个定性变量作图。
① 柱状图。首先,可以通过柱状图了解一下数据中钻石纯净度的频数分布。纯净度是度量钻石内含物多少的指标。其内含物越少,光芒折射越多,也就越显得璀璨。根据美国宝石学院(Gemological Institute of America, GIA)的标准,钻石净度可分为FL,IF,VVS1,VVS2,VS1,VS2,SI1-SI2-SI3,I1-I2-I3等级别,从前到后依次降低。
前文讲过,ggplot2采用了图层叠加的原理,因此画柱状图以及其他任何图形之前,要建立一个坐标轴的图层,即定义好数据及坐标映射。采用ggplot(data, mapping)来设定用哪个数据的哪些变量来作图,将其结果作为第一个图层p,然后在p的基础上叠加柱状图映射命令geom_bar即可(见图23)。
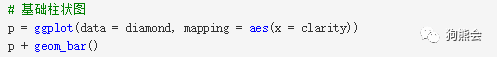
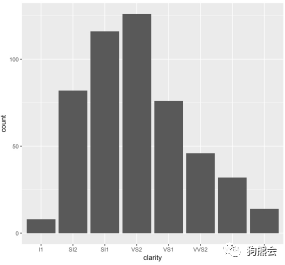
图23 钻石纯度分布直方图
从图23可以看出,数据中大多数钻石的纯净度分布在SI1,SI2,VS2这三种类型上,频数均分布在100上下。其中SI1净度肉眼看不到瑕疵,SI2净度用肉眼仔细看可以看到瑕疵,并且内含物通常是黑色的,而VS2比SI1稍微好点,但差异基本可以忽略不计。所以可以得到结论:数据中所测量的钻石的纯净度大多在中等水平,像比较高端的微瑕疵水平VS1,VVS1,VVS2等则频数较低,当然更低端的I1级也较少。
② 饼图。通过饼图来了解数据的切工cut分布。所谓切工,并非指钻石形状,而是指钻石刻面的切磨比例和排列以及工艺质量。钻石的亮度、闪烁和火彩都是由切工决定的。
不像前文介绍的基础画图包,ggplot2包并没有专门做饼图的命令,它实际上是通过坐标系的转换来完成的,将直角坐标系转换为笛卡尔坐标系。在ggplot2的图形语法中,这两种坐标系属于同一个成分,可以自由拆卸替换,笛卡尔坐标系中的饼图正是直角坐标系中的柱状图,其中柱状图中的高就对应饼图中的角度。因此用这个包画饼图时需要先画出柱状图,然后通过坐标系的转化来做出最后的大饼。下面通过拆解步骤来详细讲解。
step 1: 统计频数(此处也可使用table),即统计出每一类别的频数。

step 2: 画出堆积柱状图(见图24)。此处采用cut变量来进行颜色区分。geom_bar中设置图形的宽度为1,并采用原始未经过变换的数据作图(设置参数stat=”identity”)。

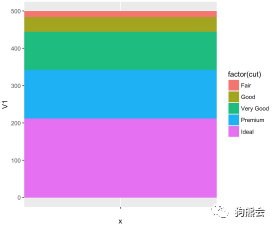
图24 钻石切工堆积柱状图
step 3 : 变成极坐标,并加比例标签。这里最重要的是使用coord_polar来进行极坐标变换,并同时通过geo_text来为饼图加标签,特别注意的是上面累计柱状图的总频数为500,换到极坐标时可以简单地理解为一圈有500度,因此在设定标签位置pos时需要用到累计频数,并加以适当调整,确保数值标签显示在合适的位置(见图25)。

图25 钻石切工饼图雏形
step 4: 做其他修饰(去框调色)。最后要加一些其他的参数来对这个图进行美观度调整,比如通过scale_fill_manual来手动设定饼图的颜色(其中values用来设定各个颜色的取值),通过theme来把坐标轴、外圈的标记去掉等(见图26)。

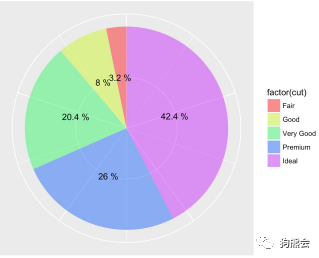
图26 钻石切工分布饼图
从图26可以看出,在切工方面,数据集所搜集的钻石大多集中在Ideal,Premium和very good 这三个等级上,可以说集中在了非常好的水平。那具体这些等级有什么含义呢?严格来说,它们是用来衡量钻石切割打磨后获得的各部分围绕中心点的水平对称程度的,是一项评价切工的重要指标。对称的切割会令闪光及火彩更加强烈。国外钻石证书关于对称性的评价比较详细,从高到低依次有ideal (ID),excellent (EX)(或Premium),very good (VG),fair (F),poor (P),所以数据中的钻石大多是切工方面的上乘品。
2)一个定量变量作图。
① 直方图。通过直方图来了解最关心的问题——这批钻石的价格分布。对一个定量变量做直方图,首先仍然是将数据映射到坐标轴上,然后通过geom_histgram来设定做直方图即可(“图层叠加”的好处,就是可以将数据映射在坐标轴,做好底层图后,再通过不同命令随意添加各种合适的图,一个+就连接起了各个图层和参数)(见图27)。
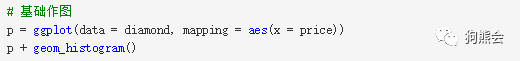
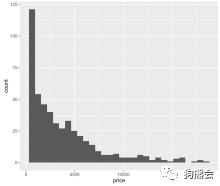
图 27 钻石价格分布直方图
直方图27显示,这批钻石的价格以低价为主,大部分钻石集中在5000美元以下,也有部分钻石在5000~10000美元之间,再昂贵的钻石数量就很少了。
同样,如果想观察更多数据上的细节,可以通过变换组距组数来完成,仅需要在geom_histogram中设定参数bins或binwidth就可实现(见图28)。
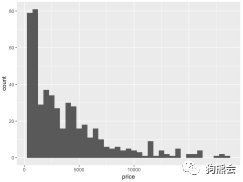
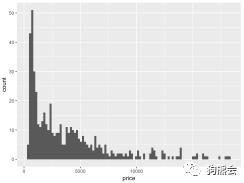
图28 不同组距下钻石价格分布对比直方图
变换了组数之后,便可在分布图中看到更多的小突起,比如在10000美元以上的钻石中,在12000美元、14000美元左右的钻石也相对较多。
② 折线图。还有一类变量也是定量变量,一般以时间序列的格式呈现,这时通常会用折线图来表现它随时间变化的趋势。折线图的绘制通过+geom_line即可完成(见图29)[由于diamonds数据中并不包含时间序列格式的变量,因此用《人民的名义》搜索指数来展示折线图的画法。]。

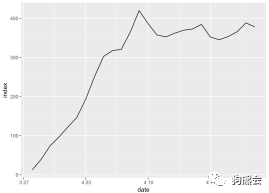
图29 《人民的名义》搜索指数分布折线图(原始版)
如果想让图形更好看,还可以通过添加colour参数及+geom_area函数来绘制一个面积图(见图30)。
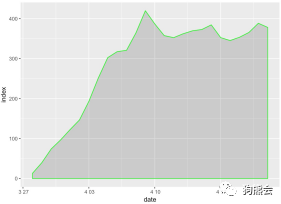
图30 《人民的名义》搜索指数分布折线图(阴影版)
从图30可以看出,《人民的名义》自2017年3月28日开播以来,搜索指数一路飙升;到4月9日左右到达谷顶,搜索指数高达410多,这段时间也是该剧持续的涨粉之路;4月9日之后每天的搜索指数就稳定在350~400之间,说明这段时间的搜索主要来自日常追剧的固定粉丝们。
3)为两个变量画图。
① 定性变量与定量变量——箱线图。前文讲到,箱线图也是表现定量变量,尤其是对比分组定量变量分布的利器。在ggplot2包中,直接使用geom_boxplot做出箱线图,里面的参数设置更加直观:用a分组就把aes中的x设置为a,探求因变量b的分布就把aes中的y设置为b。如果还想用颜色更明显地区分效果,还可以通过fill把柱子的填充色映射为分类变量。接表1的数据,切工是度量一个钻石闪不闪亮的重要指标,那么高等级的切工是否对应着高价格呢?可以用分组箱线图来回答这个问题(见图31)。
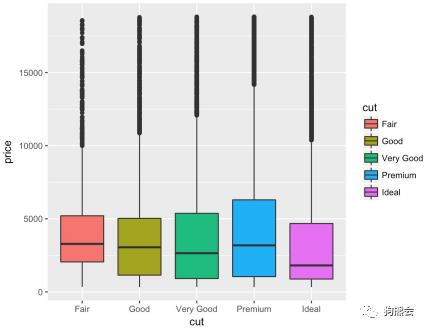
图31 钻石不同切工的价格对比箱线图(原色版)
从图31来看,切工的等级与价格没有特别明显的关系,可见钻石的贵贱还需要综合其他很多因素来看出。
若想更换柱子的颜色同样可以采用scale_fill_manual函数。在绘制饼图时展示了将value直接设置为彩虹色rainbow的情形,这里展示另一种设定方法——直接指定各个颜色的顺序来为柱子填色(见图32)。
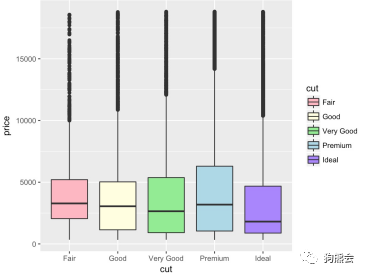
图32 钻石不同切工的价格对比箱线图(填色版)
关于如何配色可参阅“ggplot2颜色讲解专场”[ http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/],它完整地讲解了ggplot2设置颜色的方式以及所自带的模板配色;“各种流行配色一览”[ https://zhuanlan.zhihu.com/p/20908976]归纳了当今流行软件中各种内置的优秀配色方案以及《华尔街日报》、《商业周刊以》、《经济学人》等专业商业杂志的配色方案可供参考。
② 两个定量变量——散点图。
下面介绍如何绘制用来展示两个定量变量相关性的散点图。操作思路和箱线图一样,即做出基本图层p,然后加geom_point就绘制出了散点图。下面可以看看平时经常让大家哗然的“鸽子蛋”是不是真的价格比其他钻石高(见图33)。
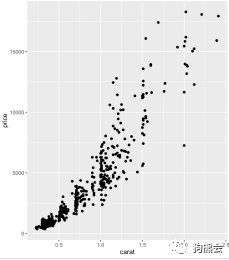
图33 钻石克拉数与价格分布散点图(原始版)
如图33所示,钻石的克拉数越大,其价格就越高,而且趋势也略显陡峭,这也就意味着:在大钻石中,其克拉数每增长一个单位,价格就涨得更快。
当然,可以画的散点图并不都是这么单调,加上几个参数,就可以轻松把其他几何属性映射进去:比如想分出不同纯净度的钻石点来,就可以做出图34。
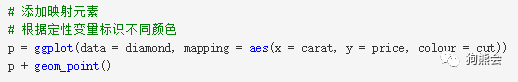
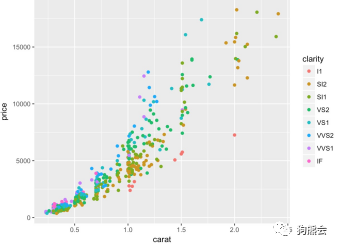
图34 钻石克拉数与价格分布散点图(颜色对应纯净度)
从图34可以看出,越是高等级对应的鲜艳颜色(IF,VVVS1,VVVS2)的点就越集中在图的左下角,越是低等级对应的较暗的颜色(SL1,SL2)越集中在图的右上方,也就说,数据测量的这批钻石,纯净度高的大多是克拉数小的,因此也就多处于低价位区间;纯净度低的大多是克拉数大的,所以也有个别处于较高的价位。如果映射一个类别数目小的定性变量可能就看得更清楚了,读者可以自行变换尝试。
当然,谈到可以映射为颜色的变量,并不非要是定性变量,定量变量也照样可以。比如把z(即钻石的垂直高度)作为颜色添加进去,就可以发现更重的钻石也是更高的(见图35)。
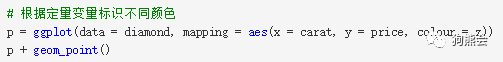
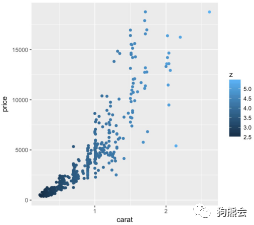
图35 钻石克拉数与价格分布散点图(颜色对应高度)
除了增加映射,还可以把各种想用的、常用的操作直接加在后面,比如,y值做了变换后再画图,直接加scale_y_log10即可对y值取以10为底的对数(见图36);要增加一条拟合曲线,则通过stat_smooth即可,这就是ggplot2的美妙与方便之处(见图37)。
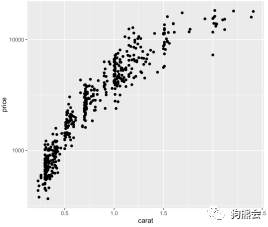
图 36 钻石克拉数与对数价格分布散点图(原始版)
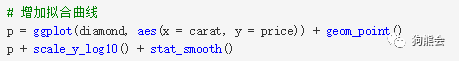
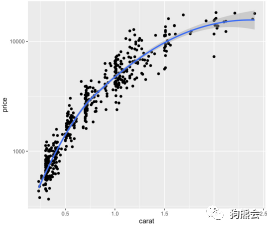
图 37 钻石克拉数与对数价格分布散点图(增加拟合曲线)
③ 两个定性变量——柱形图。下面介绍用于表现两个定性变量关系的分组箱线图如何用ggplot2包实现。
前面用柱状图看了钻石中各等级纯净度的频数分布,如果想在其中同时看下不同等级的钻石对应的切工如何,就可以设计把这两个变量交叉,画出累计柱状图,即直接通过fill把切工等级映射为颜色(见图38)。

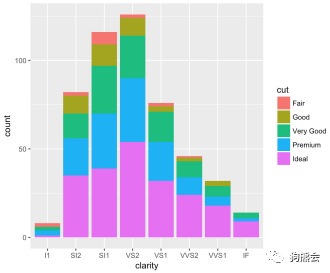
图 38 不同净度、切工等级的钻石分布累计柱状图
从图38可以看出,不只可以看到不同纯净度钻石的分布,还可以看到每种纯净度的钻石中切工等级为Ideal的最多,等级为Fair的最少,尤其是比较高的等级VVS1,IF等级别中几乎全是Very Good以上级别的切工,这些都是让人眼前一亮的精品钻石。
如果想看cut为Ideal,Premium,Very Good级别的钻石在哪个纯净度上分布最多,可能分组柱状图表现得更明显。那么只需要在geom_bar中设定position=”dodge”,累积柱状图就变成分组柱状图了(见图39)。
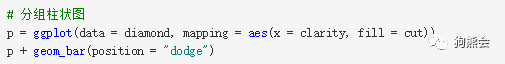
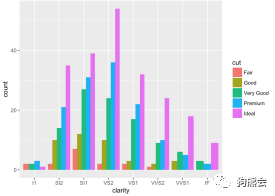
图 39 不同净度、切工等级的钻石分布分组柱状图
从图39可以清楚看出各个级别的切工质量基本都集中分布在纯净度为VS2的等级。当然如果觉得颜色太多太艳,还可以参考前文介绍的颜色设置来任意调整。
上边介绍了ggplot2的基本使用方法,领略了一种全新的基于图层的绘图思想,以及一些具体统计图形的绘制方法,并穿插了诸如更换颜色、增加分面、添加拟合线以及对数据进行对数变换等小技巧[更多的技巧可通过谷歌搜索,以及参照Wickham的《ggplot2:数据分析与图形艺术》一书获得。]。
3、交互数据可视化
前面的内容介绍了通过把数据可视化,可以方便地将信息一览无余,而如果让图像动起来,甚至能随着我们的操作而展示不同细节的信息,这样无疑会让我们的探索更加有趣,也让我们有机会以不同的视角观察不同的数据。
下面就来介绍一款可以实现交互可视化的R包——plotly,看看它在表现常规统计图形时有哪些新意。
1. plotly简介
plotly是个交互式可视化的第三方库,官网提供了Python, R, Matlab, Java, Excel的接口,因此可以很方便地在这些软件中调用plotly,从而实现交互式的可视化绘图(如图40)。
图40 Plotly官网主页https://plot.ly/
下面就来介绍如何在R中调用plotly。使用plotly绘制各种图形时,其基本语法的构造类似于ggplot2包,均是采用同一个函数plot_ly来画图,仅仅通过设置其中的参数type来变换图表类型。
(1)一个定性变量。
1)柱状图。柱状图主要用来表现一个定性变量的频数分布,这是最常见的用法。其核心是可以比较不同数字的大小,因此除了比较频数,它还可以在很多场景下使用,比如比较不同组别的均值,甚至还可以成为表现模型系数的好工具[更多用途请阅读《丑图百讲|这根柱子,你咋不上天呢?(下)》(进入狗熊会公众号,输入关键词“这根柱子(下)”阅读原文)。]。下面以不同组别的平均值画柱状图的例子讲解交互式柱状图的画法。
“雾霾”是近年大家密切关注的问题。这里采用自行搜集的北京市2016年1月1日至2016年12月17日PM2.5每日均值的数据来演示柱状图的画法。
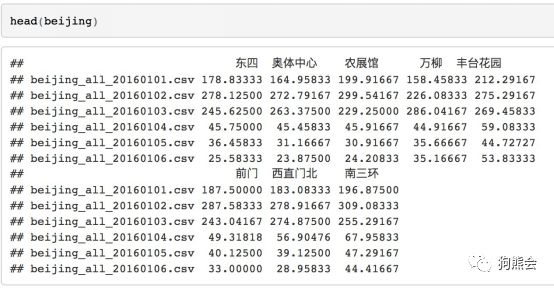
数据的情况如表3所示,每一列代表搜集的地点。
表3 北京市2016年1月1日至2016年12月17日PM2.5每日均值数据
先计算出柱状图高度所对应的量,即各个地点每日的平均PM2.5值,提取出地点名称,就可以输入函数plot_ly来做柱形图了。
plot_ly函数的基本使用方法是:plot_ly(x,y,type),其中x用来设定映射到横坐标的向量,y用来设定映射到纵坐标的向量,type可以设置图像的类型,此处将type设置为bar就可以绘出柱状图(见图41)。当把鼠标移动到任何一根柱子上面,就会实时显示出它的数值和对应的地点(这就是交互图形的意思)。

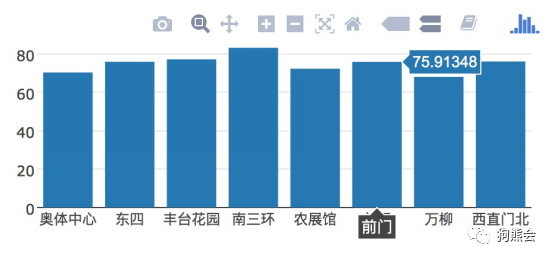
图41 北京各地区PM2.5分布柱状图
从图41可以直观看出,南三环、丰台花园以及西直门北等北京南部地区的PM2.5污染较严重,这与新闻报道中的结论基本一致。北京大部分的工业企业都集中在偏南部的地区,导致这里各种生产气体排放量巨大,再加上南部空气的扩散条件较差,因此南部的一些地区诸如大兴、通州、丰台等常常是PM2.5的重灾区,这在数据中也得到了体现。
如果不仅满足于此,还想通过颜色的设置突出这一年中平均PM2.5值最高的地区,还可以通过marker来设置。marker中color可以用来设置各个柱子对应的颜色,将想要的颜色的RGB值以及alpha透明度值输入rgba就可以达到目的了(见图42)。

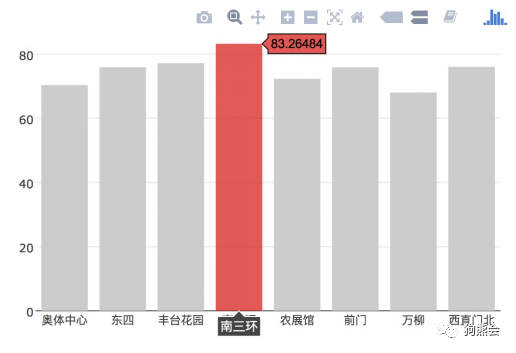
图42 突出显示平均PM2.5最高的地区
2)饼图。饼图是一个表现整体各个组成部分比例的好工具,可是常规的饼图往往为了简洁,只会用标签显示各个类别的数值或者比例之一,可如果还想知道另一项怎么办呢?这时交互式的饼图就派上用场了。
一般来讲,画饼图之前要先统计出各个类别的频数,形成一个数据框,然后用它来绘制图形。这里为简单起见,直接生成一组示例数据pieData,其中value是各类别的频数,group是类别的标号。

有了这个数据,就可以输入plot_ly,设置type=”pie”来绘制图形。不同于绘制柱状图,这里不需要设定x,y,而关键是要设定labels和values的参数,labels用来设置类别名称,values用来指定类别的频数。
这样就画出了一个基本的图形(见图43)。鼠标移到相应类别,就会显示出它的其他信息。
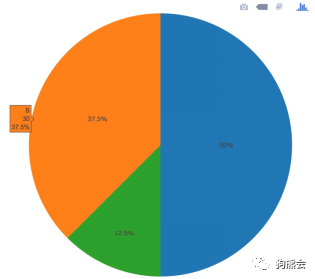
图43 动态饼图
当然,如果R版本不够新,很可能输入以上命令后,R会跳出如图44的一幅图:附带着横纵坐标以及多余的网格线。
图44 旧R版本的动态饼图
如果不希望看到如图44这样的布局,就要用到一个调整图片外观的函数layout,通过设置对应的参数为FALSE,可以一一把它们去掉。

再来稍加解释一下其中的参数,xaxis,yaxis是用来修整横纵坐标轴的。将showgrid设置为FALSE是用来去除图后面的网格线;zeroline为FALSE可用来设置不显示横(纵)坐标的坐标轴;把showticklabels设置为FALSE可以擦掉原先分布在坐标轴上的数字。
(3)一个定量变量。
1)直方图。在表现定量变量的分布时,当然不能缺少直方图。通过直方图可以看到大部分的样本分布在哪里,虽然直观,但也缺乏细节。如果不仅要展示整体,也要展示关键部分的细节数据,那么动态图就是必然选择了。
下面以苹果公司的股价数据为例。搜集了2010年2月1日至2016年12月19日苹果公司股价情况,包括它当天股票的开盘价、最高、最低点、收盘价、成交量以及调整收盘价。数据的基本结构如表3-4所示。
表4 2010年2月1日至2016年12月19日苹果公司股价情况
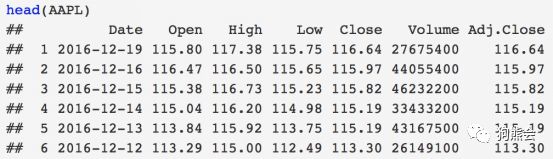
该数据的每一列都是连续数据,此处以第6列Volume成交量为例来展示近几年苹果公司股票成交量的分布情况。读者可以仿照示例来观察其他变量的分布。
直方图同样采用plot_ly函数绘制,但是需要注意是:设置type”=histogram”;x坐标的命名方法是有符号“~”,表示将Volume变量映射到x轴上(见图45)。
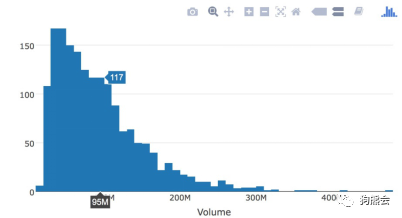
图 45 苹果公司股票成交量直方图
从图45可以看出,由于成交量的数值都是在百万级别上的,所以plot_ly自动将数值做简化显示,用M表示一百万(Million)。总体来讲,苹果股价的成交量分布很广泛,从最低的1140多万股的成交量到最高4亿7千多万股的成交量都有,但大多数时候,成交量集中在5千多万到1亿股之内,且以较低的区间为主。
需要注意的是,在交互图形中,对于坐标轴、纵横坐标的内容、直方图的标题等的设定,是否可以直接在plot_ly函数中加入title或者xlab这类的参数来命名呢?答案是否定的。如果需要设置图形的标题和纵横轴内容,需要另外采用layout函数来单独定义。在饼图中,通过设置xaxis(yaxis)中的三个参数成功把坐标轴等零件隐藏了起来,同样,此处需要设置坐标轴标题时,同样可以用xaxis中的参数完成。这里为了让图片显示完整,还另外用margin增加了对图形左右下上边界的限制(见图46)。

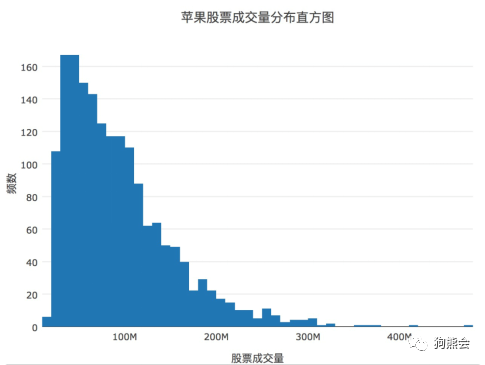
图 46 添加画图元素的股票直方图
因此,当要调整涉及图形外观方面的属性时,就可以用layout函数,比如标题属性、横纵坐标轴属性、图例属性、图形外边距属性,这些属性包括字体、颜色、尺寸等。
2)折线图。表达时间连续变量变化趋势的另一种有效工具是时间序列的折线图。仍然采用苹果公司股票数据来做说明。
我们知道,公司在发布一款新产品时,对发布的时间点一定是精挑细选,因为新品发行对该公司的股价、旧产品的市场发行量都有很大的影响。那么数据是否也支持这种说法呢?股价是否真的在发布新品之时会有波动呢?下面用股价数据来回答这个问题。
这里将采用折线图观察苹果公司每日的调整收盘价变化。绘制折线图的关键参数在于设置type=”scatter”,且同时设置mode=”lines”。(回想用R的基础绘图包中是不是也基于同样的思路?)
图47展示了plot_ly的交互功能既可以同步显示鼠标所在地方,也可以通过上面的一排排小按钮对其进行不同放大缩小等操作,比如右图就是把图放大,只看顶峰的那一部分图。


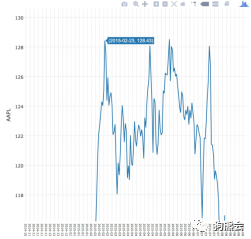
图 47 苹果公司股价动态折线图
从图47可以看出,从2010年2月1日至2016年12月19日,苹果公司的股价总体呈现上升状况,第一个小高峰出现在2012年的第一季度和第三季度,之后有所回落;大概到2013年4月左右跌到谷底,之后继续攀升,分别在2015年2—7月攀至谷顶,达到了每股124美元的调整后收盘价。
观察到这些规律之后,可能会问:那些股价攀升或者下跌剧烈的时间里,苹果公司发生了什么,跟新品发布有多大关系呢?于是,另外搜集iphone4至iphone7所有手机的发布时间,将它标记在图中,就能看到一些蛛丝马迹(见图48)。
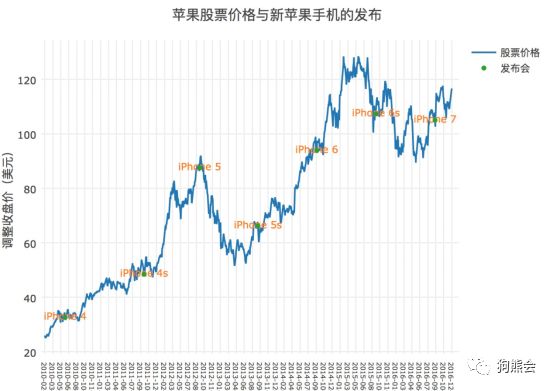
图 48 添加新手机发布标签的折线图
果不其然,在新品发布之时,苹果公司的股价都会发生一些波动,尤其以iphone5,iphone5s,iphone7等手机发布时最为明显。大部分手机在发布时股价都会产生新一轮攀升,但iphone5却不然,发布之后的一段时间里股票持续下跌。据当时媒体报道称,这可能与产品功能令投资者失望、销量表现令人失望有关系。

图 49 网友吐槽iphone5
(4)两个变量。
下面使用小说数据来介绍两个变量的动态图部分。
1)两个定量变量——散点图。散点图常常是表达两个定量变量的关系的利器。如果关心当一个网络小说的总点击数越多,它的总评论数是否也越多时,就可以画出散点图来观察(见图50)。用plot_ly画基本散点图的命令为:
特别要注意的是:除了要设置type=”scatter”散点图外,还需要以符号“~”来引出作图变量。
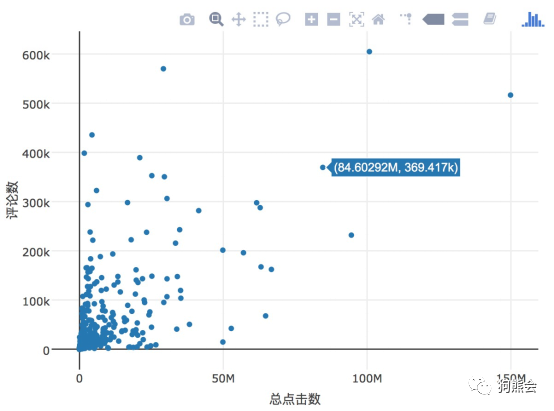
图 50 网络小说点击数与评论数散点图
从图50可以看出,对于大部分小说来说,其点击数越多,带来的评论数也越多(但有一些小说在点击数不多的情况下也有不俗的评论量,感兴趣的读者可以探究一下原因),绝大部分小说的总点击数在5千万次之内,但个别极受欢迎的小说的总点击数能达到1亿多次,评论也在50万条以上,也就是图50中最右边的点,该点对应的是起点中文网的白金作家天蚕土豆所著的《斗破苍穹》。

图 51 《斗破苍穹》小说封面(来自网络)
2)定量VS定性变量——分组箱线图。分组箱线图可谓是表现定性变量与定量变量交叉关系的首选工具,自然也能用其探索小说数据中的种种规律。最近小王想读一本字数比较少、方便速读的小说,那他该选择哪种类型的小说呢?也许,一个简单的箱线图就能帮小王回答这个问题。这里选择数据中已经完结或者接近尾声的小说来绘图,仅仅需要更改type=” box”,color映射为小说类型就可以了(见图52)。
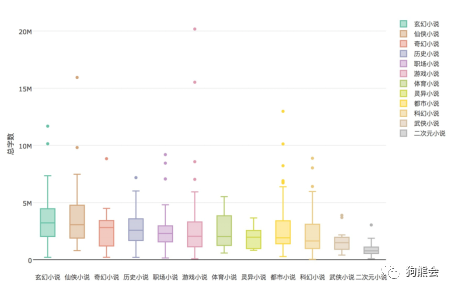
图 52 不同小说字数对比箱线图
从图52可以看出,从平均水平(中位数)来看,玄幻小说、仙侠小说和奇幻小说通常都是大部头的代表类型,而大部分二次元小说、武侠小说则字数较少,基本在150万字以下,因此,想快速刷小说的读者可以先从武侠、二次元入手。
3)两个定性变量——分组柱状图。再来看看分组柱状图如何用plot_ly实现。在表1的数据变量说明中还注意到,有一列变量标记了该小说是公众作品还是VIP作品,公众作品就是所有人都可以浏览全部小说的作品,而VIP作品则是公众只能过过眼瘾,只有VIP才可以饱览全貌的小说,那么各个类别的小说,是主要为了积攒人气而推出的公众作品多,还是只为服务高端用户而推出的VIP作品多?下面做一个简单的分组柱状图便可一目了然了(见图53)。
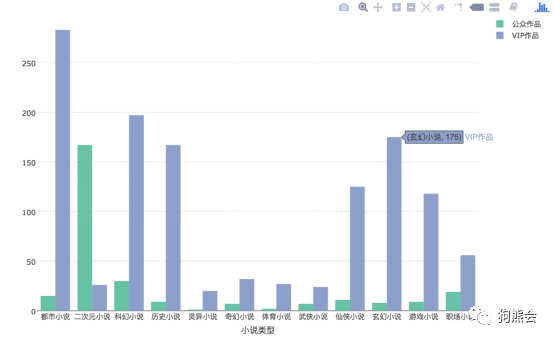
图 53 不同类型小说的公众作品及VIP作品数量柱状图
从图53可以看出,大部分小说都主要服务于VIP用户,推出的VIP作品最多,但其中只有一个特别醒目,就是二次元小说,这种类型的小说的公众作品远远高于VIP作品,可能是为了给更广大的用户推广的目的。
那么图3-53是怎样画出来的呢?这有点类似ggplot2的映射思维,将变量“小说类型”映射到横轴,将变量“小说性质”映射为颜色即可,另外需特别注意的是,画分组柱状图应设置type=”histogram”。

几个世纪以来,静态的可视化方式让人们获得了很多对数据的理解,如今通过对数据交互式的探索,就更能深入到这些图表的细节,改变我们所观察的角度,体察数字背后的故事。希望大家都能善用图表,透过它们看到不一样的世界。
- 本文固定链接: https://maimengkong.com/image/1260.html
- 转载请注明: : 萌小白 2022年10月7日 于 卖萌控的博客 发表
- 百度已收录
